数据获取、整理与应用
一、构建可靠数据
1. 图像和视频数据爬取
1.1 四种数据获取方法
- 开源数据集

https://huggingface.co/datasets
特点:(1)数据质量高(2)成本低
外包平台(Amazon Mechanical Turk,阿里众包,百度数据众包,京东微工等)

可定制化 成本较高
自己采集与标注

特点:(1)质量高(2)效率低(3)成本高
通过网络爬虫获取

特点:(1)成本低(2)速度快
1.2 爬虫工具使用
支持Google,Bing,百度等网站,有GUl使用界面

https://github.com/sczhengyabin/Image-Downloader
1.3 视频网站爬虫
支持主流视频网站(腾讯视频,抖音等)

https://github.com/iawia002/lux
使用方法:lux[可选参数]http://...(视频网址)

爬虫合集(几乎所有可以爬取的中文网址)

https://github.com/facert/awesome-spider
2.数据获取与整理
2.1数据检查与清洗
检查与清洗(图片)
去除不好的图片

检查与清洗(文本)
- 去除停用词和特殊符号
- 停用词是指在文本中出现频率较高,但是对文本的语义分析没有帮助的词语,如“的”、“是”等。
- 特殊符号是指标点符号、数字等对于文本的语义分析没有帮助,甚至可能干扰模型的学习。

归一化
格式归一化

内容纠错
拼写纠正、语法纠正等

2.2 数据去重
名字或分辨率不同,实际内容相同的数据

相似数据
连续视频帧,相似文档,噪声污染等

常见的相似度准则:MSE距离,leveshtein距离,DNN特征距离....
2.3 数据集划分
数据子集划分
训练集,验证集,测试集3个不相交的子集

以训练集训练模型;以验证集评估模型,寻找最佳的参数;以测试集测试模型一次,其误差近似为泛化误差。
数据集难度划分
常见数据集难度划分

为什么要划分不同的难度等级呢?以人像抠图为例

3.数据标注
3.1 数据标注概述
数据标注成为行业
数据标注师成为人工智能领域中的一个新兴并且重要的就业岗位

数据标注公司
云测数据,数据堂,龙猫数据,星尘数据,文德数慧,格物钛,点我科技,曼孚科技,梦动科技,标贝科技,笑猫科技.....

数据众包平台
国外的Amazon Mechanical Turk,国内的百度众包等

3.2 数据标注工具
Label Studio
多模态数据标注工具,可以标注语音、文本,图片、视频等数据

# Requires Python >=3.8 pip install label-studio # Start the server at http://localhost:8080 label-studio
Label Studio功能
支持各类常见的机器学习任务

支持常见视觉任务:分类、目标检测、语义分割,视觉问答、OCR等任务标注
支持常见文本任务:问答、机器翻译、命名实体识别、文本摘要、关系抽取等任务标注
支持常见语音任务:语音识别、说话人分割等任务标注
Label Studio基本使用流程
注册账号->创建项目->导入文件->任务配置->人工标注->导出结果

3.3 视觉任务标注
目标检测标注

命名实体识别标注

3.4 语言任务标注案例
命名实体标注

二、数据增强方法与实践
1.数据增强
1.1 什么是数据增强
多少数据才能满足项目要求
项目中到底需要多少数据

任务类型有关,越精细任务要求越多
任务难度有关,ImageNet(每类约500个),Place365(每类约5000个)
精度要求有关(学术任务,工业级产品)
什么是数据增强
数据增强(Data Augmentation)也叫数据扩增、数据增广

在不实质性的增加数据的情况下,从有限的数据产生更多变种,让有限的数据产生等价于更多数据的价值
数据增强的作用
降低数据采集成本

充分利用已有的数据进行数据增强:可以大幅度降低数据采集与标注成本
模型过拟合风险降低,提高模型泛化能力


方法分类
总体包括单样本数据增强,多样本数据增强,样本生成等

1.2 单样本数据增强方法
采用固定的预设规则进行数据扩增

单样本几何变换-翻转
水平翻转和垂直翻转

单样本几何变换-裁剪与缩放
裁剪图片的感兴趣区域(ROI)

单样本几何变换-旋转
旋转

单样本几何变换-仿射与透视变换
仿射与透视变换是综合的几何类变换

单样本像素变换-添加噪声
不规则的黑色或者彩色斑点

单样本像素变换-添加模糊
减少各像素点值的差异,实现像素的平滑化

单样本像素变换-颜色扰动
通过对不同通道的分量进行修改,改变颜色、亮度、对比度等

单样本像素变换-更多操作
各种图像处理方法都可以使用

单样本像素变换-综合变换
特定图像的数据增强

1.3 多样本数据增强方法
基于多个样本的图像处理操作,实现新样本的合成

SamplePairing操作:随机选择两张图片分别经过基础数据增强操作处理后,叠加合成一个新的样本,标签为原样本标签中的一种。
Mixup
对图像x和标签y都进行线性插值

CutMix
直接复制粘贴样本

Mosaic
4张图片合并在一起用于训练

1.4 样本生成方法
当下两大主流的生成模型
- 生成对抗网络(Generative Adversarial Network)与扩散模型(Diffusion Model)

2.数据增强库imgaug实践
2.1 什么是imgaugi
一个非常强大的图像数据增强库
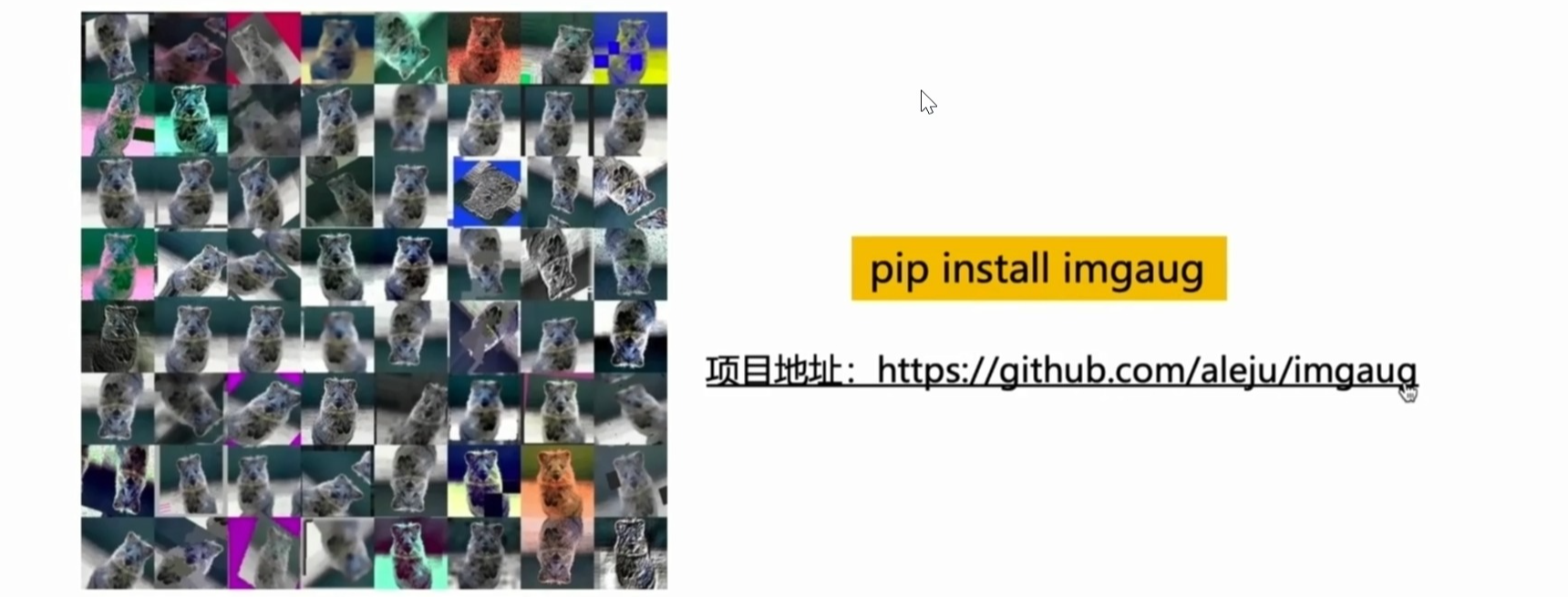
imgaug可以做什么
- 各类常见数据增强操作
- affine transformations, perspective transformations, contrast changes, gaussian nqise, dropout of regions, hue/saturation changes, cropping/padding, blurring...
- 支持的数据类型:
- Images(uint8), Heatmaps (float32), Segmentation Maps(int), Masks (bool), Keypoints/Landmarks (int/float coordinates), Bounding Boxes (int/float coordinates), Polygons (int/float coordinates), Line Strings(int/float coordinates)
imgaug数据增强对象
augmenters.Sequential:组合一系列增强函数

2.2 imgaug数据增强操作
基本数学操作
添加噪声,删除像素等系列方法
# Add: 对图像每个像素统一加上一个固定值或从指定范围内采样的值(整体变亮/变暗) # AddElementwise: 对图像每个像素独立地加上一个随机值(可产生更局部的亮度变化) # AdditiveGaussianNoise: 添加高斯分布(正态分布)的加性噪声 # AdditiveLaplaceNoise: 添加拉普拉斯分布的加性噪声(比高斯噪声有更尖锐的峰值和更厚的尾部) # AdditivePoissonNoise: 添加泊松分布的加性噪声(模拟光子计数等物理过程中的噪声) # Multiply: 对图像每个像素统一乘以一个标量(整体调整对比度或亮度) # MultiplyElementwise: 对图像每个像素独立地乘以一个随机因子(局部对比度扰动) # Cutout: 随机遮盖图像中一个或多个矩形区域(常用于提升模型鲁棒性) # Dropout: 随机将部分像素置为零(模拟传感器坏点或信息丢失) # CoarseDropout: 将图像划分为大块,然后随机丢弃某些块(比普通Dropout更粗粒度) # Dropout2D: 类似Dropout,但以通道为单位进行丢弃(适用于多通道图像) # TotalDropout: 以一定概率将整张图像完全置黑(极端情况下的数据增强) # ReplaceElementwise: 按概率随机将像素替换为指定值(可用于模拟异常像素) # ImpulseNoise: 添加脉冲噪声(即随机将像素设为极亮或极暗,类似椒盐噪声的一种形式) # SaltAndPepper: 同时添加“盐”(白色像素)和“胡椒”(黑色像素)噪声 # CoarseSaltAndPepper: 在较粗的网格上应用SaltAndPepper噪声(块状椒盐噪声) # Salt: 仅添加“盐”噪声(白色噪点) # CoarseSalt: 在粗粒度上添加“盐”噪声 # Pepper: 仅添加“胡椒”噪声(黑色噪点) # CoarsePepper: 在粗粒度上添加“胡椒”噪声 # Invert: 反转图像颜色(如黑白反转,RGB -> 255 - RGB) # Solarize: 对亮度高于阈值的像素进行颜色反转(模拟过度曝光效果) # JpegCompression: 模拟JPEG压缩伪影(通过降低图像质量引入压缩噪声)噪声类案例

删除类案例

几何变换操作
翻转,平移,仿射变换等
# ScaleX: 沿图像水平方向(X轴)进行缩放(拉伸或压缩) # ScaleY: 沿图像垂直方向(Y轴)进行缩放(拉伸或压缩) # TranslateX: 沿水平方向平移图像(左右移动) # TranslateY: 沿垂直方向平移图像(上下移动) # Rotate: 将图像绕其中心旋转指定角度 # HorizontalFlip: 水平翻转图像(等价于 Fliplr) # ShearX: 沿 X 轴方向进行剪切变换(使图像倾斜,保持 Y 不变) # VerticalFlip: 垂直翻转图像(等价于 Flipud) # ShearY: 沿 Y 轴方向进行剪切变换(使图像倾斜,保持 X 不变) # Fliplr: 左右翻转图像(水平镜像) # PiecewiseAffine: 对图像应用分段仿射变换(局部扭曲,模拟非刚性形变) # Flipud: 上下翻转图像(垂直镜像) # PerspectiveTransform: 应用透视变换(模拟从不同视角观察图像的效果) # Affine: 组合执行仿射变换(包括缩放、平移、旋转、剪切等) # ElasticTransformation: 对图像施加弹性形变(模拟柔软物体的局部扭曲效果) # Rot90: 将图像逆时针旋转90度的整数倍(快速且无插值损失) # WithPolarWarping: 将图像从笛卡尔坐标系转换到极坐标系(或反向),产生径向扭曲效果 # Jigsaw: 将图像分割成若干块并随机打乱位置(模拟拼图效果,增强局部不变性)翻转与拼图案例

仿射变换案例

模糊操作
# GaussianBlur: 使用高斯核对图像进行模糊处理(模拟光学散焦或降噪)
# AverageBlur: 使用均值滤波器对图像进行模糊(每个像素替换为其邻域平均值)
# MedianBlur: 使用中值滤波器对图像进行模糊(有效去除椒盐噪声,保留边缘)
# BilateralBlur: 使用双边滤波器进行模糊(在平滑图像的同时较好地保留边缘信息)
# MotionBlur: 模拟相机或物体运动造成的线性运动模糊效果
# MeanShiftBlur: 应用均值漂移滤波对图像进行非参数化模糊(常用于图像分割前处理)
高斯模糊,均值模糊等

颜色操作
# WithColorspace: 在指定颜色空间(如HSV、LAB等)中执行子增强操作,再转回原空间
# WithBrightnessChannels: 在分离出亮度通道的颜色空间中对亮度进行增强操作
# MultiplyAndAddToBrightness: 同时对图像亮度进行缩放和偏移(组合调整明暗)
# MultiplyBrightness: 仅对图像的亮度通道进行乘法缩放(整体变亮或变暗)
# AddToBrightness: 仅对图像的亮度通道添加偏移值(提升或降低明暗)
# WithHueAndSaturation: 在HSV等颜色空间中对色相(Hue)和饱和度(Saturation)进行增强
# MultiplyHueAndSaturation: 同时对色相和饱和度进行缩放(可能改变颜色和鲜艳度)
# MultiplyHue: 仅对色相通道进行缩放(改变图像主色调)
# MultiplySaturation: 仅对饱和度通道进行缩放(增强或减弱颜色鲜艳程度)
# RemoveSaturation: 将图像的饱和度设为零(转换为灰度效果,但保留原始亮度结构)
# AddToHueAndSaturation: 同时对色相和饱和度通道添加偏移值(微调颜色和饱和度)
# AddToHue: 仅对色相通道添加偏移(轻微改变颜色色调)
# AddToSaturation: 仅对饱和度通道添加偏移(提升或降低色彩浓度)
# ChangeColorspace: 将图像从一种颜色空间转换到另一种(如RGB→HSV、RGB→GRAY等)
# Grayscale: 将图像转换为灰度图(可选择不同加权方式或保持单通道)
# ChangeColorTemperature: 调整图像的色温(模拟暖光或冷光照明效果)
# KMeansColorQuantization: 使用K均值聚类将图像颜色量化为有限数量的代表色
# UniformColorQuantization: 对每个颜色通道进行均匀量化(减少颜色深度)
# UniformColorQuantizationToNBits: 将每个颜色通道量化为指定比特数(如4位、5位等)
# Posterize: 减少每个颜色通道的色阶数量,产生海报化(色带)艺术效果
- 颜色偏移、饱和度调整等

亮度操作
# GammaContrast: 使用伽马校正调整图像对比度(通过非线性变换调整亮度分布)
# SigmoidContrast: 使用S型曲线调整图像对比度(可增强中间调对比度)
# LogContrast: 使用对数曲线调整图像对比度(增强暗区细节)
# LinearContrast: 使用线性变换调整图像对比度(简单地增加或减少对比度)
# AllChannelsCLAHE: 对所有颜色通道应用限制性自适应直方图均衡化(CLAHE),以改善对比度而不产生过多噪声
# CLAHE*: 对单个颜色通道应用限制性自适应直方图均衡化(CLAHE),用于增强特定通道的对比度(注意:可能是指定特定通道而非所有通道)
# AllChannelsHistogramEqualization: 对所有颜色通道应用直方图均衡化,以提高整个图像的对比度
# HistogramEqualization: 对单一颜色通道应用直方图均衡化,通常用于灰度图像或特定颜色通道,以提升其对比度
对比度,直方图等


尺度变换操作
# Resize: 调整图像大小到指定尺寸(宽度和高度)
# CropAndPad: 裁剪并填充图像以达到目标尺寸,可指定裁剪区域及填充方式
# Pad: 对图像进行填充(四周增加额外像素),可用于保持图像在变换过程中不丢失信息
# Crop: 从图像中裁剪出一个子区域,根据给定的位置和大小
# PadToFixedSize: 将图像填充至固定的最小尺寸,如果图像小于该尺寸
# CropToFixedSize: 从图像中裁剪出固定大小的区域
# PadToMultiplesOf: 将图像填充至宽度和高度为指定数值倍数的尺寸
# CropToMultiplesOf: 从图像中裁剪出宽度和高度为指定数值倍数的区域
# CropToPowersOf: 从图像中裁剪出宽度和高度为指定基数的幂次方的区域
# PadToPowersOf: 将图像填充至宽度和高度为指定基数的幂次方的尺寸
# CropToAspectRatio: 根据指定的宽高比裁剪图像
# PadToAspectRatio: 根据指定的宽高比填充图像
# CropToSquare: 裁剪图像使其成为正方形(宽度等于高度)
# PadToSquare: 填充图像使其成为正方形(宽度等于高度)
缩放,裁剪,填充等

卷积变换操作
卷积,池化,边缘计算等
augmenters.convolutional
# Convolve: 对图像应用自定义卷积核,实现如模糊、锐化、浮雕等效果
# Sharpen: 使用预设卷积核增强图像边缘,使细节更清晰
# Emboss: 应用浮雕卷积核,使图像呈现立体雕刻效果
augmenters.pooling
# AveragePooling: 对图像进行平均池化,降低分辨率并平滑内容
# MaxPooling: 对图像进行最大池化,保留局部区域中最亮或最显著的像素
# MinPooling: 对图像进行最小池化,保留局部区域中最暗的像素
# MedianPooling: 对图像进行中值池化,在下采样的同时抑制噪声
augmenters.edges
# Canny: 使用Canny算法检测图像中的强边缘,输出二值边缘图
# EdgeDetect: 使用通用边缘检测卷积核(如Sobel)突出图像边界
# DirectedEdgeDetect: 指定方向(如水平/垂直)进行定向边缘检测,强调特定朝向的边缘

2.3 数据增强库imgaug使用
使用步骤
使用Sequential来封装数据增强函数
import numpy as np import imgaug.augmenters as iaa # 载入库 def load_batch(batch_idx): """ 模拟读取图片的函数 输入:batch_idx - 批次索引 输出:uint8类型的图像数组,RGB格式 """ # 模拟128张32x32的RGB图像,值随batch_idx变化 return np.zeros((128, 32, 32, 3), dtype=np.uint8) + (batch_idx % 255) def train_on_images(images): """训练主函数(示例)""" # 在这里实现实际的训练逻辑 pass # 定义数据增强操作序列 # - 0.5概率进行随机水平翻转 # - 随机裁剪1~16个像素 # - 高斯模糊 seq = iaa.Sequential([ iaa.Fliplr(0.5), # 50%概率水平翻转 iaa.Crop(px=(1, 16), keep_size=False), # 随机裁剪 iaa.GaussianBlur(sigma=(0, 3.0)) # 高斯模糊 ]) # 训练代码主循环 for batch_idx in range(100): # 加载批次数据 images = load_batch(batch_idx) # 输入图像必须是[N,H,W,C]格式的张量,或者图像数组,Uint8格式 # 应用数据增强 images_aug = seq(images=images) # 使用增强后的图像进行训练 train_on_images(images_aug)
简单案例
单张图像的数据增强
import numpy as np import imgaug as ia import imgaug.augmenters as iaa import imageio # 设置随机种子以保证结果可复现 ia.seed(1) # 创建16张64x64的RGB图像(使用quokka示例图像) images = np.array( [ia.quokka(size=(64, 64)) for _ in range(16)], dtype=np.uint8 ) # 定义数据增强序列 seq = iaa.Sequential([ iaa.Fliplr(0.5), # 50%概率水平翻转 iaa.Crop(percent=(0, 0.1)), # 随机裁剪0-10% iaa.Sometimes( 0.5, # 50%概率应用 iaa.GaussianBlur(sigma=(0, 0.5)) # 高斯模糊 ), iaa.AdditiveGaussianNoise( loc=0, scale=(0.0, 0.05 * 255), # 噪声强度 per_channel=0.5 # 50%概率独立应用于每个通道 ) ], random_order=True) # 随机顺序执行增强 # 应用数据增强 images_aug = seq(images=images) # 将增强后的图像排列成网格(4列) grid_image = ia.draw_grid(images_aug, cols=4) # 保存图像 imageio.imwrite("example_segmaps.jpg", grid_image)
复杂案例
对同一个batch内容不同图像使用不同参数
# coding:utf8 import numpy as np import imgaug as ia import imgaug.augmenters as iaa # 设置随机种子,确保每次运行结果可复现 ia.seed(1) ## 创建图像矩阵 (16, 64, 64, 3) # - 16: 图片数量 # - 64, 64: 图片高度和宽度 # - 3: RGB三通道 images = np.array( # 使用列表推导式创建16张相同的考拉图片 [ia.quokka(size=(64, 64)) for _ in range(16)], dtype=np.uint8 # 图像数据类型,0-255的整数 ) # 考拉图片的来源: # 1. imgaug库内置了一个示例图片库 # 2. ia.quokka() 函数返回一张考拉(quokka)的图片 # 3. 这张图片是imgaug开发者提供的测试用图 # 4. 实际位置通常在imgaug安装目录下的data文件夹中 # 查看图片信息 print(f"图像数组形状: {images.shape}") print(f"图像数据类型: {images.dtype}") print(f"像素值范围: {images.min()} ~ {images.max()}") # 定义数据增强序列 seq = iaa.Sequential([ iaa.Fliplr(0.5), # 以0.5的概率进行水平翻转 iaa.Crop(percent=(0, 0.1)), # 随机裁剪0-10%的边缘 # 对50%的图片应用高斯模糊 iaa.Sometimes( 0.5, # 应用概率 iaa.GaussianBlur(sigma=(0, 0.5)) # 模糊程度 ), # 添加高斯噪声 iaa.AdditiveGaussianNoise( loc=0, # 噪声均值 scale=(0.0, 0.05*255), # 噪声标准差(最大为12.75) per_channel=0.5 # 50%的概率独立应用于每个通道 ), ], random_order=True) # 随机顺序执行增强操作 # 应用数据增强 images_aug = seq(images=images) # 将16张增强后的图片排列成4x4的网格 grid_image = ia.draw_grid(images_aug, 4) # 保存网格图片 import imageio imageio.imwrite(r"D:\BaiduNetdiskDownload\【0】源码+PDF课件+电子书\源码+PDF课件\第9周资料\imgaug\imgaug\example.jpg", grid_image) print("图片已保存!")