PyTorch数据处理与网络模型构建
一、PyTorch入门与应用
1.安装PyTorch
1.1 安装
访问官网:PyTorch
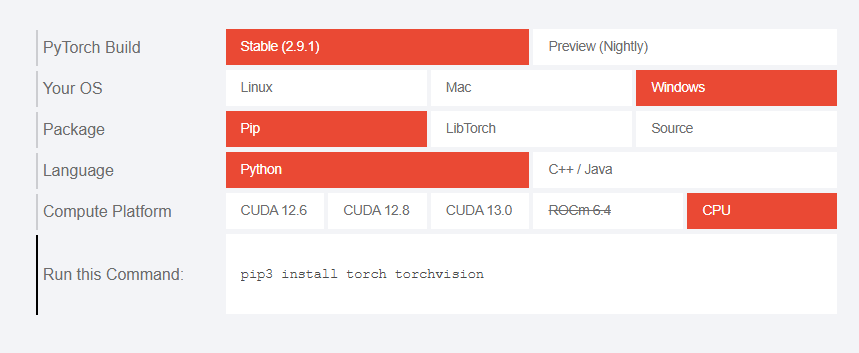
安装以前的版本 install previous versions of PyTorch

pip install torch==1.13.1+cpu torchvision==0.14.1+cpu torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cpu
1.2 显卡驱动和安装CUDA
更新Nvidia显卡驱动和安装CUDA
更新显卡驱动

安装CUDA
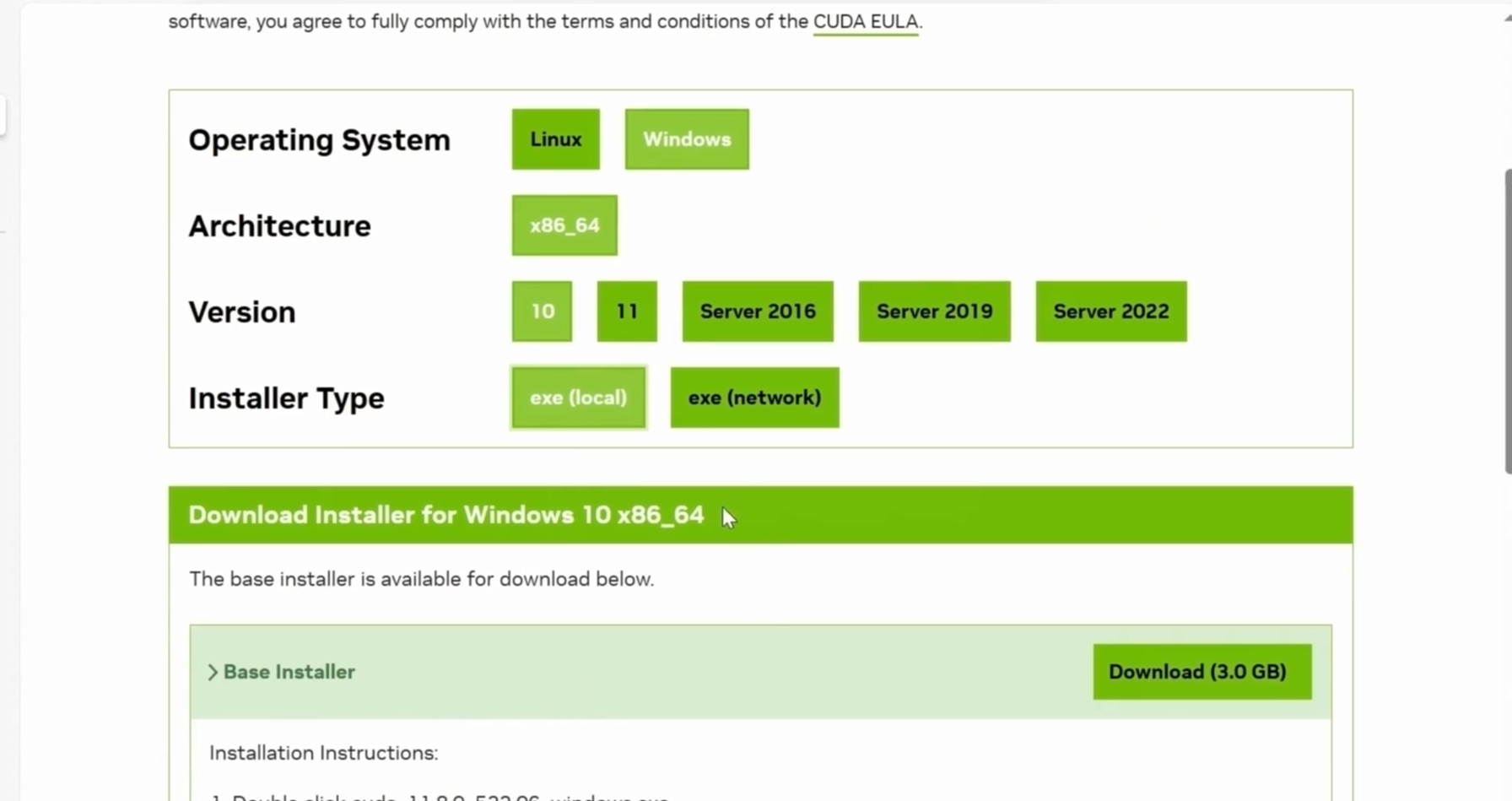
安装CUDNN

安装PyTorch
import torch # 检查CUDA是否可用 print(torch.cuda.is_available()) # 查看PyTorch版本 print(torch.__version__)
2.Tensor的操作
2.1定义Tensor
什么是Tensor
- Tensor是PyTorch中基本的数据格式
- 数据在网络内部运算时的格式是Tensor
- 各种输入都要转为Tensor才能输入到网络中
Tensor格式如下所示

import torch
# 创建一个PyTorch张量(tensor),表示一个2行3列的矩阵
# 第一行包含三个浮点数:0.3565, 0.1826, 0.6719
# 第二行包含三个浮点数:0.6695, 0.5364, 0.7057
tensor_data = torch.tensor([[0.3565, 0.1826, 0.6719], # 第一行数据
[0.6695, 0.5364, 0.7057]], # 第二行数据
dtype=torch.float32, # 指定张量数据类型为32位浮点数
device='cuda:0') # 指定张量存储在第一个CUDA设备(GPU)上
# 打印张量信息
print("张量数据:")
print(tensor_data)
print(f"\n张量形状: {tensor_data.shape}") # 输出: torch.Size([2, 3])
print(f"张量设备: {tensor_data.device}") # 输出: cuda:0
print(f"数据类型: {tensor_data.dtype}") # 输出: torch.float32
Tensor属性
import torch
# 创建一个形状为 (3, 4) 的随机张量,元素值在 [0, 1) 区间内,数据类型默认为 float32
tensor = torch.rand(3, 4)
# 打印张量的形状(维度信息)
print(f"Shape of tensor: {tensor.shape}")
# 打印张量的数据类型(如 torch.float32)
print(f"Datatype of tensor: {tensor.dtype}")
# 打印张量所在的设备(如 cpu 或 cuda:0)
print(f"Device tensor is stored on: {tensor.device}")
Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu
Tensor存储的数据
import torch
# 定义一个 Python 嵌套列表作为原始数据
data = [[1, 2], [3, 4]]
# 将列表转换为 PyTorch 张量(tensor)
X_data = torch.tensor(data)
# 打印张量内容(注意变量名大小写必须一致)
print(X_data)
tensor([[1, 2],
[3, 4]])
import torch
import numpy as np
# 创建一个 NumPy 数组(2x2)
np_array = np.array([[1, 2],
[3, 4]])
# 将 NumPy 数组转换为 PyTorch 张量
# 注意:from_numpy() 创建的张量与原 NumPy 数组共享内存
X_np = torch.from_numpy(np_array)
# 打印张量(注意变量名大小写一致)
print(X_np)
tensor([[1, 2],
[3, 4]], dtype=torch.int32)
import torch
# 定义一个 Python 嵌套列表作为原始数据
data = [[1, 2], [3, 4]]
# 将列表转换为 PyTorch 张量
X_data = torch.tensor(data)
# 创建一个与 X_data 形状相同、所有元素为 1 的张量,
# 并保持其数据类型(这里是 int64)
x_ones = torch.ones_like(X_data)
print(f"Ones Tensor:\n{x_ones}\n")
# 创建一个与 X_data 形状相同的随机张量,
# 但显式指定数据类型为 float32(torch.float)
x_rand = torch.rand_like(X_data, dtype=torch.float)
print(f"Random Tensor:\n{x_rand}\n")
Ones Tensor:
tensor([[1, 1],
[1, 1]])
Random Tensor:
tensor([[0.8532, 0.7764],
[0.4441, 0.4497]])
import torch
# 定义张量的形状为 (2, 3)
shape = (2, 3)
# 创建一个在 [0, 1) 区间内均匀分布的随机浮点张量
rand_tensor = torch.rand(shape)
# 打印随机张量(注意 f-string 的正确写法)
print(f"Random Tensor:\n{rand_tensor}\n")
Random Tensor:
tensor([[0.4215, 0.8932, 0.1024],
[0.7653, 0.3321, 0.9087]])
import torch
# 定义张量的形状为 (2, 3)
shape = (2, 3)
# 创建一个全 1 张量,形状为 shape,默认数据类型为 float32
ones_tensor = torch.ones(shape)
# 创建一个全 0 张量,形状相同
zeros_tensor = torch.zeros(shape)
# 打印全 1 张量
print(f"Ones Tensor:\n{ones_tensor}\n")
# 打印全 0 张量
print(f"Zeros Tensor:\n{zeros_tensor}")
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
Tensor存储的位置
import torch
# 定义张量形状
shape = (2, 3)
# 创建一个随机张量(默认在 CPU 上)
rand_tensor = torch.rand(shape)
print("Original tensor (CPU):")
print(rand_tensor)
# 如果 CUDA 可用,将张量移到 GPU
if torch.cuda.is_available():
rand_tensor = rand_tensor.cuda()
print("\nTensor moved to GPU:")
print(rand_tensor)
# 将张量移回 CPU(无论当前在哪)
cpu_tensor = rand_tensor.cpu()
print("\nTensor moved back to CPU:")
print(cpu_tensor)
2.2 Tensor实操
import torch
# 创建一个一维 PyTorch 张量(默认在 CPU 上,数据类型为 int64)
tensor1 = torch.tensor([1, 2, 3])
# 打印原始张量
print(tensor1)
# 打印张量所在的设备(通常是 cpu)
print(tensor1.device)
# 尝试将张量移动到 GPU(如果 CUDA 可用)
# 注意:这里原代码写的是 cudaO(),是拼写错误,应为 cuda()
# 如果系统没有 GPU 或 CUDA 不可用,这行会报错!
# 因此更安全的做法是先检查 torch.cuda.is_available()
try:
tensor_1 = tensor1.cuda() # 将张量从 CPU 移动到 GPU(返回新张量)
print(tensor_1)
print(tensor_1.device) # 此时设备应为 cuda:0(如果有 GPU)
except RuntimeError as e:
print("CUDA 不可用,无法将张量移至 GPU:", e)
tensor_1 = tensor1 # 若失败,保持在 CPU
# 将张量从当前设备(可能是 GPU)移回 CPU
tensor_1 = tensor_1.cpu()
print(tensor_1)
print(tensor_1.device) # 现在设备一定是 cpu
如果电脑未安装coda则异常
Traceback (most recent call last):
File "D:\BaiduNetdiskDownload\【0】源码+PDF课件+电子书\源码+PDF课件\第10周资料\demo.py", line 9, in <module>
tensor_1 = tensor1.cudaO()
AttributeError: 'Tensor' object has no attribute 'cudaO'
更推荐的安全写法(避免直接调用 .cuda()):
import torch
tensor1 = torch.tensor([1, 2, 3])
print("原始张量:", tensor1)
print("设备:", tensor1.device)
# 安全地选择设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tensor_on_device = tensor1.to(device)
print("\n移动到设备后:", tensor_on_device)
print("设备:", tensor_on_device.device)
# 移回 CPU
tensor_back_to_cpu = tensor_on_device.cpu()
print("\n移回 CPU 后:", tensor_back_to_cpu)
print("设备:", tensor_back_to_cpu.device)
2.3 Tensor运算
索引
import torch
# 创建一个 4x4 的标准正态分布随机张量(均值为0,标准差为1)
tensor = torch.randn(4, 4)
print("原始张量:")
print(tensor)
# 打印第0行(索引为0的行)
print(f"第0行: {tensor[0]}")
# 打印第0列(所有行的第0个元素)
print(f"第0列: {tensor[:, 0]}")
# 打印最后一列(... 表示所有前面的维度,-1 表示最后一个元素)
print(f"最后一列: {tensor[..., -1]}")
# 将第1列(索引为1)的所有元素设为 0
tensor[:, 1] = 0
# 打印修改后的张量
print("\n将第1列置零后的张量:")
print(tensor)
原始张量:
tensor([[-0.3543, -1.2641, 2.6698, 0.3090],
[ 1.2639, -0.4035, 0.8048, 0.2832],
[-1.1713, 1.1481, -0.3168, -0.1328],
[ 0.9467, 0.1091, 0.4642, -0.7512]])
第0行: tensor([-0.3543, -1.2641, 2.6698, 0.3090])
第0列: tensor([-0.3543, 1.2639, -1.1713, 0.9467])
最后一列: tensor([ 0.3090, 0.2832, -0.1328, -0.7512])
将第1列置零后的张量:
tensor([[-0.3543, 0.0000, 2.6698, 0.3090],
[ 1.2639, 0.0000, 0.8048, 0.2832],
[-1.1713, 0.0000, -0.3168, -0.1328],
[ 0.9467, 0.0000, 0.4642, -0.7512]])
Process finished with exit code 0
算术运算
import torch
# 创建两个 2x3 的张量(稍作扩展,便于演示按行/列求和)
A = torch.tensor([[1, 2, 3],
[4, 5, 6]], dtype=torch.float32)
B = torch.tensor([[7, 8, 9],
[10, 11, 12]], dtype=torch.float32)
print("张量 A:")
print(A)
print("\n张量 B:")
print(B)
# ----------------------------
# 1. 矩阵乘法 (A @ B.T) —— 因为 A 是 2x3,B 是 2x3,不能直接相乘
# 所以我们用 A (2x3) 和 B 转置 (3x2) 相乘 → 结果为 2x2
# ----------------------------
matrix_mul = A @ B.T # B.T 是 B 的转置
print("\n✅ 矩阵乘法 (A @ B.T):")
print(matrix_mul)
# ----------------------------
# 2. 逐元素运算(要求形状相同,A 和 B 都是 2x3,符合)
# ----------------------------
elem_mul = A * B
elem_add = A + B
elem_sub = A - B
print("\n✅ 逐元素乘法 (A * B):")
print(elem_mul)
print("\n✅ 逐元素加法 (A + B):")
print(elem_add)
print("\n✅ 逐元素减法 (A - B):")
print(elem_sub)
# ----------------------------
# 3. 求和操作(Sum)
# ----------------------------
# (a) 对整个张量所有元素求和(标量)
total_sum = A.sum()
print(f"\n✅ A 所有元素之和: {total_sum}")
# (b) 按列求和(dim=0:压缩行,保留列)→ 结果形状 (3,)
col_sum = A.sum(dim=0)
print(f"✅ A 按列求和 (dim=0): {col_sum}")
# (c) 按行求和(dim=1:压缩列,保留行)→ 结果形状 (2,)
row_sum = A.sum(dim=1)
print(f"✅ A 按行求和 (dim=1): {row_sum}")
# (d) 保持维度(keepdim=True)—— 便于后续广播操作
row_sum_keepdim = A.sum(dim=1, keepdim=True) # 形状变为 (2, 1)
print(f"✅ A 按行求和(保持维度):\n{row_sum_keepdim}")
拼接
import torch
# 创建两个形状为 (1, 4) 的行向量(二维张量)
tensor_1 = torch.tensor([[1, 2, 3, 4]]) # shape: (1, 4)
tensor_2 = torch.tensor([[5, 6, 7, 8]]) # shape: (1, 4)
# 沿 dim=0 拼接:在行方向堆叠(增加行数)
# 结果形状: (2, 4)
cat_dim0 = torch.cat([tensor_1, tensor_2], dim=0)
print("沿 dim=0 拼接(垂直拼接):")
print(cat_dim0)
# 沿 dim=1 拼接:在列方向拼接(增加列数)
# 结果形状: (1, 8)
cat_dim1 = torch.cat([tensor_1, tensor_2], dim=1)
print("\n沿 dim=1 拼接(水平拼接):")
print(cat_dim1).
沿 dim=0 拼接(垂直拼接):
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])
沿 dim=1 拼接(水平拼接):
tensor([[1, 2, 3, 4, 5, 6, 7, 8]])
2.4 Tensor数据转换
Numpy转换Tensor
import torch
import numpy as np
# 创建一个包含5个1的一维numpy数组
n = np.ones(5)
# 将numpy数组转换为PyTorch张量
t = torch.from_numpy(n)
# 打印numpy数组和转换后的PyTorch张量
print("Numpy array:")
print(n)
print("\nPyTorch tensor:")
print(t)
Numpy array:
[1. 1. 1. 1. 1.]
PyTorch tensor:
tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
Tensor转换Numpy
import torch
# 创建一个包含5个1的一维张量(你可以改成任意形状,如 (3, 4))
t = torch.ones(5) # 或 torch.ones((5,)),或 torch.ones(3, 4)
# 将 PyTorch 张量转换为 NumPy 数组
# 注意:张量必须在 CPU 上,且不能 requires_grad=True
n = t.numpy()
# 打印结果
print("PyTorch 张量:")
print(t)
print("\nNumPy 数组:")
print(n)
PyTorch 张量:
tensor([1., 1., 1., 1., 1.])
NumPy 数组:
[1. 1. 1. 1. 1.]
图片转Tensor
from PIL import Image
from torchvision import transforms
# 设置图像路径(确保文件 'image.png' 存在于当前目录或指定路径)
image_path = r'image.png' # 注意:不要在引号内加多余空格!
# 使用 PIL 打开图像
image = Image.open(image_path)
# 定义转换:将 PIL Image 转为 PyTorch Tensor
# ToTensor() 会自动将像素值从 [0, 255] 转换为 [0.0, 1.0] 的 float32 张量,
# 并将形状从 (H, W, C) 转为 (C, H, W)
transform = transforms.ToTensor()
# 应用转换
tensor_image = transform(image)
# 打印张量类型和形状
print("张量类型:", type(tensor_image))
print("张量形状:", tensor_image.shape)
print("数据类型:", tensor_image.dtype)
Tensor转图片
import torch
from torchvision import transforms
# 方法 1:创建符合 [0, 1] 范围的随机张量(推荐用于 ToPILImage)
tensor_image = torch.rand(3, 224, 224) # 值在 [0, 1) 之间,符合 float 图像要求
# 方法 2(备选):如果你坚持用 randn,需先归一化到 [0, 1]
# raw = torch.randn(3, 224, 224)
# tensor_image = (raw - raw.min()) / (raw.max() - raw.min()) # 归一化
# 定义转换:将 Tensor 转为 PIL Image
to_pil = transforms.ToPILImage()
# 执行转换
transformed_image = to_pil(tensor_image)
# 保存路径(确保有写权限)
save_path = r'from_tensor.jpg'
# 保存图像
transformed_image.save(save_path)
print(f"图像已保存至: {save_path}")
2.5 PyTorch处理图片
综合案例:PyTorch处理图片
模拟从硬盘读取一张图片,使用pytorch在显卡上进行运算,随后把运算结果保存到硬盘
import torch from torchvision import transforms from PIL import Image import os # ============================== # 配置路径 # ============================== image_path = r"image.png" save_path = r"result.png" print("🚀 开始图像处理流程...\n") # ============================== # 1. 检查输入文件是否存在 # ============================== if not os.path.exists(image_path): raise FileNotFoundError(f"❌ 输入图像文件不存在: {image_path}") print(f"✅ 找到输入图像: {image_path}") # ============================== # 2. 加载图像(PIL) # ============================== try: image = Image.open(image_path) print(f"🖼️ 原始图像模式: {image.mode}") print(f"📏 原始图像尺寸: {image.size} (宽 x 高)") except Exception as e: raise RuntimeError(f"❌ 无法打开图像: {e}") # ============================== # 3. 转换为 PyTorch Tensor # ============================== transform = transforms.ToTensor() # 自动将 [0,255] -> [0.0, 1.0],并转为 (C, H, W) tensor_image = transform(image) print(f"\n🔄 转换为 Tensor:") print(f" - 形状: {tensor_image.shape}") print(f" - 数据类型: {tensor_image.dtype}") print(f" - 设备: {tensor_image.device}") print(f" - 像素值范围: [{tensor_image.min().item():.4f}, {tensor_image.max().item():.4f}]") # ============================== # 4. 移动到 GPU(如果可用) # ============================== original_device = tensor_image.device if torch.cuda.is_available(): tensor_image = tensor_image.to('cuda') print(f"\n➡️ 已将张量移至 GPU: {tensor_image.device}") else: print(f"\n⚠️ CUDA 不可用,继续在 CPU 上操作") # ============================== # 5. 对每个像素加 0.1(模拟简单变换) # ============================== print(f"\n✨ 执行操作: tensor += 0.1") before_min, before_max = tensor_image.min().item(), tensor_image.max().item() tensor_image += 0.1 after_min, after_max = tensor_image.min().item(), tensor_image.max().item() print(f" - 操作前范围: [{before_min:.4f}, {before_max:.4f}]") print(f" - 操作后范围: [{after_min:.4f}, {after_max:.4f}]") # ⚠️ 注意:值可能超过 [0,1],ToPILImage 会自动裁剪到合法范围 if after_max > 1.0 or after_min < 0.0: print(" ⚠️ 像素值超出 [0,1] 范围,保存时将被裁剪!") # ============================== # 6. 移回 CPU 并转换为 PIL 图像 # ============================== tensor_image = tensor_image.to('cpu') print(f"\n⬅️ 已将张量移回 CPU: {tensor_image.device}") # 使用 ToPILImage 转换(自动处理 float -> uint8 和裁剪) to_pil = transforms.ToPILImage() transformed_image = to_pil(tensor_image) print(f"\n🖼️ 转换回 PIL 图像:") print(f" - 模式: {transformed_image.mode}") print(f" - 尺寸: {transformed_image.size}") # ============================== # 7. 保存结果图像 # ============================== try: transformed_image.save(save_path) print(f"\n✅ 结果图像已保存至: {os.path.abspath(save_path)}") except Exception as e: raise RuntimeError(f"❌ 无法保存图像: {e}") print("\n🎉 图像处理流程完成!")

二、数据集加载与应用
1.Dataset与Dataloader
1.1概念与定义
什么是Dataset和Dataloader?
- Dataset指定了数据集包含了什么,可以是自定义数据集,也可以是以及官方数据集
- Dataloader指定了这个数据集应该以怎样的方式进行加载
定义Dataset
自定义的Dataset格式如下所示
from torch.utils.data import Dataset class MyDataset(Dataset): def __init__(self, data, labels): """ 初始化数据集 :param data: 数据样本列表或数组 :param labels: 对应的标签列表或数组 """ self.data = data self.labels = labels def __len__(self): """ 返回数据集的大小 """ return len(self.data) def __getitem__(self, idx): """ 获取指定索引的数据样本及其标签 :param idx: 样本索引 :return: (样本, 标签) """ sample = self.data[idx] label = self.labels[idx] # 如果需要对样本进行预处理(例如转换为张量),可以在这里完成 # 这里简单返回数据和标签 return sample, label # 示例:创建一个简单的数据集实例 if __name__ == "__main__": # 假设我们有一些简单的数据和标签 data = [[1, 2], [3, 4], [5, 6]] # 示例数据 labels = [0, 1, 0] # 示例标签 # 创建数据集实例 dataset = MyDataset(data, labels) # 打印数据集大小 print(f"数据集大小: {len(dataset)}") # 获取第一个样本及其标签 sample, label = dataset[0] print(f"第一个样本: {sample}, 标签: {label}")
Dataloader格式如下所示
# 创建一个数据加载器(DataLoader),用于高效地批量加载和预处理数据
my_dataloader = DataLoader(
my_dataset, # 📦 输入:自定义或内置的 Dataset 对象(必须实现 __len__ 和 __getitem__)
batch_size=2, # 🧮 每个批次(batch)包含 2 个样本
# - 训练时常用 16/32/64/128 等;
# - 太大会导致显存不足,太小会降低训练效率。
shuffle=True, # 🔀 是否在每个 epoch 开始前打乱数据顺序
# - **训练时通常设为 True**,有助于模型泛化;
# - **验证/测试时应设为 False**,保证结果可复现。
num_workers=4 # 🏃♂️ 使用 4 个子进程并行加载数据(加速 I/O)
# - 默认为 0(主进程加载);
# - 在 Linux/macOS 上可设为 2~8 提升速度;
# - **Windows 或 Jupyter Notebook 中建议设为 0**,
# 否则可能报错或卡死(需配合 if __name__ == '__main__' 使用)。
)
1.2 综合案例
案例1:导入两个列表到Dataset
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset): # 继承自 torch.utils.data.Dataset
def __init__(self):
"""初始化数据集:定义输入 x 和标签 y"""
self.x = [i for i in range(10)] # 输入特征: [0, 1, 2, ..., 9]
self.y = [2 * i for i in range(10)] # 标签: [0, 2, 4, ..., 18]
def __len__(self):
"""返回数据集的总样本数"""
return len(self.x)
def __getitem__(self, idx):
"""
根据索引 idx 返回单个样本 (x, y)
注意:通常应转换为 torch.Tensor,否则 DataLoader 可能无法自动堆叠
"""
x_i = self.x[idx]
y_i = self.y[idx]
return x_i, y_i
# 创建数据集实例
my_dataset = MyDataset()
# 创建 DataLoader(默认 batch_size=1) shuffle 是否对数据打乱
my_dataloader = DataLoader(my_dataset, batch_size=1, shuffle=False)
# 遍历 DataLoader 并打印每个批次
print("遍历 DataLoader 中的每个样本:")
for x_i, y_i in my_dataloader:
print(f"x_i = {x_i}, y_i = {y_i}")
1.3导入Excel数据到Dataset中
案例2:导入Excel数据到Dataset
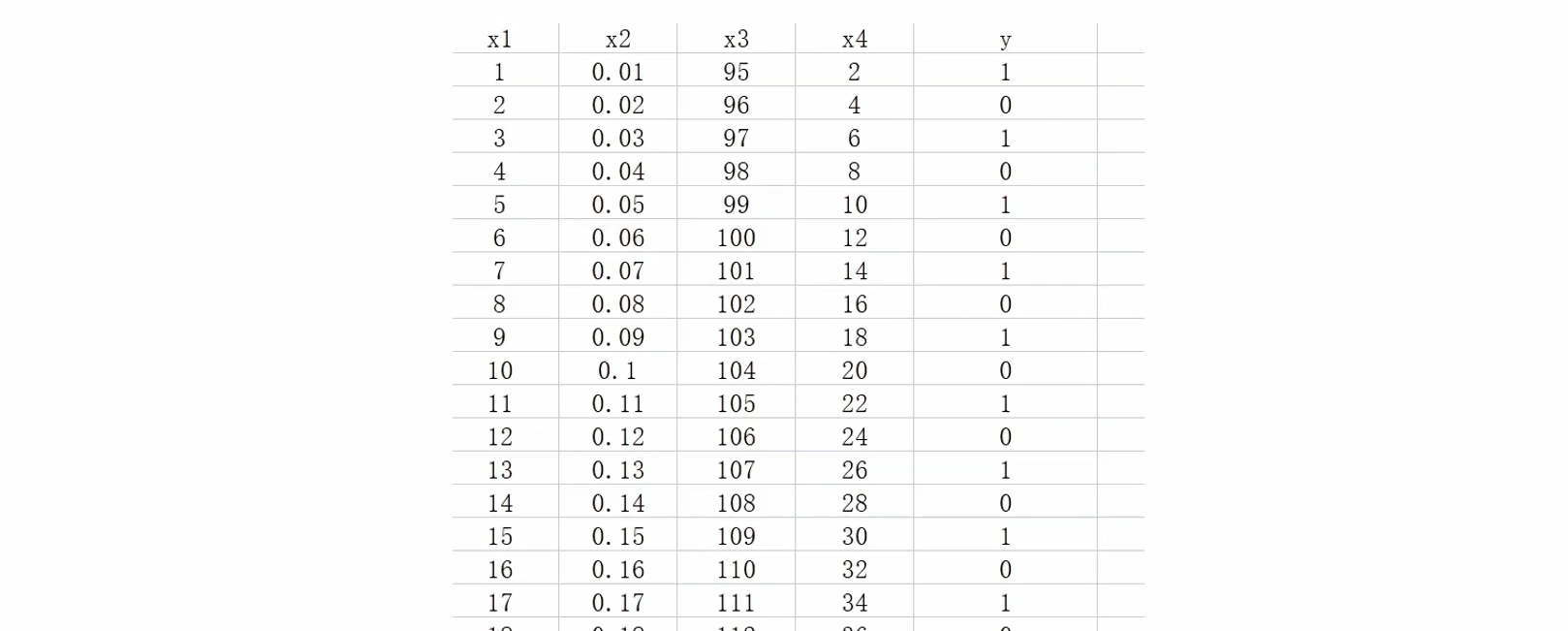
# 导入必要的库
import pandas as pd # 用于读取 Excel 文件
from torch.utils.data import DataLoader, Dataset # PyTorch 数据加载工具
# 自定义数据集类,继承自 torch.utils.data.Dataset
class MyDataset(Dataset):
def __init__(self):
"""
初始化数据集:从 Excel 文件中加载数据
"""
filename = "模仿数据读取.xlsx" # 指定 Excel 文件路径(需确保文件存在)
data = pd.read_excel(filename) # 使用 pandas 读取整个 Excel 表格
# 将各列分别赋值给实例变量(pandas Series)
# 注意:这里保留了原始数据类型(如 int64, float64)
self.x1 = data['x1']
self.x2 = data['x2']
self.x3 = data['x3']
self.x4 = data['x4']
self.y = data['y']
def __len__(self):
"""
返回数据集的总样本数量
所有列长度应一致,因此任选一列(如 x1)求长度即可
"""
return len(self.x1)
def __getitem__(self, item):
"""
根据索引 item 返回单个样本的特征和标签
返回格式: (x1_i, x2_i, x3_i, x4_i, y_i)
注意:返回的是 Python 标量或 numpy 标量,DataLoader 会自动转为 Tensor
"""
return (
self.x1[item],
self.x2[item],
self.x3[item],
self.x4[item],
self.y[item]
)
# 主程序入口(防止在 Windows 多进程下出错)
if __name__ == '__main__':
# 创建自定义数据集实例
mydataset = MyDataset()
# 创建 DataLoader,用于批量、打乱、并行加载数据
mydataloader = DataLoader(
mydataset,
batch_size=4, # 每批包含 4 个样本
shuffle=True, # 每个 epoch 打乱数据顺序(训练时常用)
num_workers=2 # 使用 2 个子进程并行加载数据(加速 I/O)
# 注意:Windows 用户若遇问题可设为 0
)
# 遍历 DataLoader,每次取出一个 batch
print("开始遍历数据加载器(每个 batch 包含 4 个样本):")
for batch_idx, (x1, x2, x3, x4, y) in enumerate(mydataloader):
print(f"\n--- Batch {batch_idx + 1} ---")
print(f"x1 = {x1}")
print(f"x2 = {x2}")
print(f"x3 = {x3}")
print(f"x4 = {x4}")
print(f"y = {y}")
1.4导入图像数据集到Dataset
# 导入必要的库
import os # 用于遍历文件系统
import cv2 as cv # OpenCV:用于读取和处理图像
import torch # PyTorch 核心库
from torch.utils.data import DataLoader, Dataset # 数据加载工具
import numpy as np # 数值计算,用于数组操作
# 自定义图像数据集类,继承自 torch.utils.data.Dataset
class MyImageDataset(Dataset):
def __init__(self):
"""
初始化数据集:遍历指定目录,收集所有图像路径及其对应标签。
假设目录结构为:
datasets/animals/
├── cat/
│ ├── cat1.jpg
│ └── cat2.png
├── dog/
│ ├── dog1.jpg
│ └── dog2.png
└── bird/
├── bird1.jpg
└── ...
每个子文件夹名(如 'cat')代表一个类别。
"""
image_root = r"datasets" # 图像根目录(原始字符串,避免转义问题)
self.file_path_list = [] # 存储所有图像的完整路径
dir_name = [] # 临时存储子文件夹名称(类别名)
self.labels = [] # 存储每个图像对应的标签 ID(整数)
# 使用 os.walk 递归遍历目录
for root, dirs, files in os.walk(image_root):
# 第一次进入时,dirs 是根目录下的子文件夹(即类别名)
if dirs:
dir_name = sorted(dirs) # ✅ 建议排序,确保标签顺序一致(重要!)
# 遍历当前目录下的所有文件
for file_i in files:
# 过滤非图像文件(可选增强)
if not file_i.lower().endswith(('.png', '.jpg', '.jpeg')):
continue # 跳过非图像文件
# 构建完整文件路径
file_i_full_path = os.path.join(root, file_i)
self.file_path_list.append(file_i_full_path)
# 提取当前图像所属的类别名(取路径最后一级目录名)
label = root.split(os.sep)[-1] # os.sep 兼容 Windows/Linux 路径分隔符
# 将类别名映射为整数 ID(基于 dir_name 列表的索引)
try:
label_id = dir_name.index(label)
except ValueError:
# 理论上不会发生,但增加健壮性
print(f"警告:未知类别 {label},跳过文件 {file_i_full_path}")
continue
self.labels.append(label_id)
# 打印数据集统计信息(调试用)
print(f"✅ 加载完成!共 {len(self.file_path_list)} 张图像,{len(dir_name)} 个类别")
print(f"类别列表: {dir_name}")
def __len__(self):
"""返回数据集的总样本数量"""
return len(self.file_path_list)
def __getitem__(self, item):
"""
根据索引 item 加载并预处理单张图像,返回 (图像张量, 标签)
注意:此方法会被 DataLoader 多进程调用,应尽量轻量。
"""
# 1. 读取图像(BGR 格式,HWC 布局)
img = cv.imread(self.file_path_list[item])
# 安全检查:防止图像损坏或路径错误
if img is None:
raise FileNotFoundError(f"无法读取图像: {self.file_path_list[item]}")
# 2. 调整图像尺寸为 256x256
img = cv.resize(img, dsize=(256, 256)) # (H, W, C)
# 3. 转换通道顺序:OpenCV 是 BGR,且布局为 HWC;
# 但 PyTorch 期望 CHW(通道在前),且通常希望是 RGB(可选)
# ⚠️ 当前代码使用 np.transpose(img, (2,1,0)) 是 **错误的**!
# 正确做法应为:(H, W, C) → (C, H, W),即 axis 顺序 (2, 0, 1)
#
# ❌ 错误:(2,1,0) → C, W, H (宽高颠倒!)
# ✅ 正确:(2,0,1) → C, H, W
#
# 同时建议转换 BGR → RGB(虽然不影响训练,但可视化更自然)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB) # 可选:转为 RGB
img = np.transpose(img, (2, 0, 1)) # ✅ 正确:HWC → CHW
# 4. 转为 PyTorch 张量(注意:cv.imread 返回 uint8,范围 [0,255])
img_tensor = torch.from_numpy(img).float() # 转为 float32(训练常用)
# 或者保留为 byte:torch.from_numpy(img).byte()
# 5. 获取标签
label = self.labels[item]
return img_tensor, label
# 主程序入口(Windows 多进程必需)
if __name__ == '__main__':
# 创建数据集实例
my_image_dataset = MyImageDataset()
# 创建 DataLoader
my_dataloader = DataLoader(
my_image_dataset,
batch_size=4, # 每批 4 张图像
shuffle=True, # 打乱顺序(训练时常用)
num_workers=0 # ⚠️ Windows 建议设为 0;Linux 可设为 2~4
)
# 遍历一个 batch 进行测试
print("\n🔍 测试 DataLoader 输出格式:")
for x_i, y_i in my_dataloader:
print(f"图像张量形状: {x_i.shape}") # 应为 torch.Size([4, 3, 256, 256])
print(f"标签: {y_i}") # 应为长度为 4 的 LongTensor
break # 只打印第一个 batch
1.5 导入官方数据集
案例4:导入官方数据集
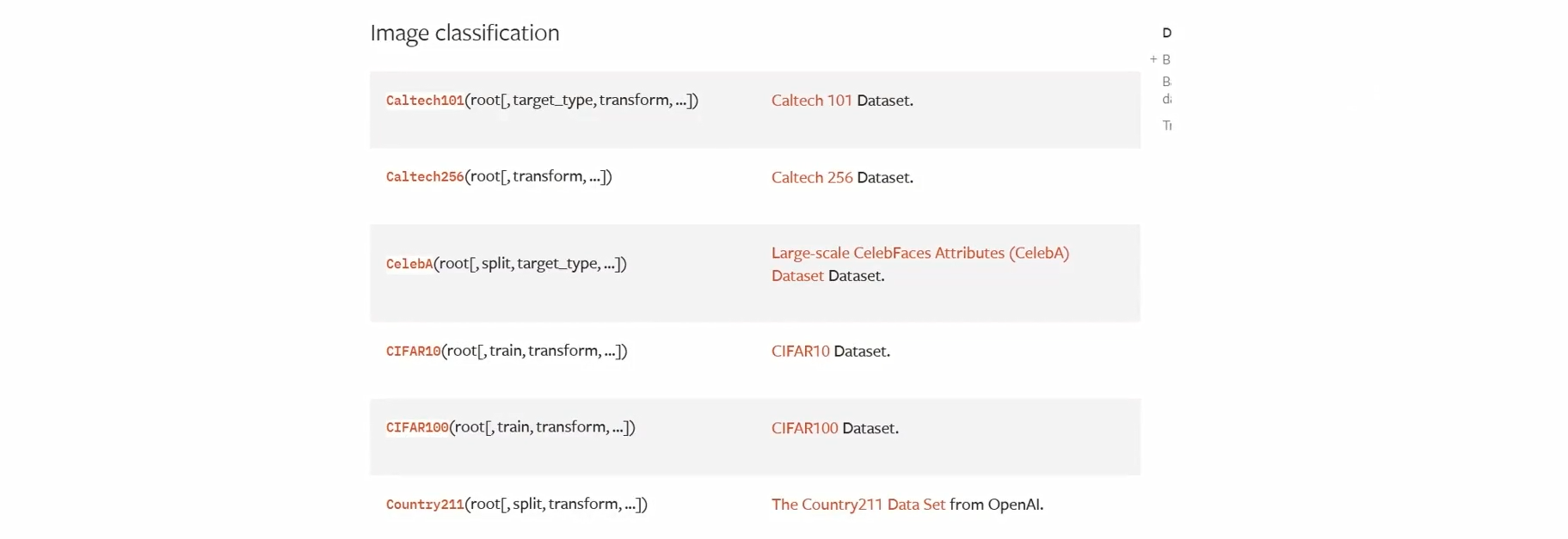
数据集 — Torchvision 0.24 文档 - PyTorch 文档
imagenet_data = torchvision.datasets.ImageNet('path/to/imagenet_root/')
data_loader = torch.utils.data.DataLoader(imagenet_data,
batch_size=4,
shuffle=True,
num_workers=args.nThreads)
# 导入必要的库
import torch # PyTorch 核心库,用于张量计算(类似于 numpy)以及构建和训练深度学习模型
import torchvision # PyTorch 的计算机视觉库,提供了流行的数据集、模型架构和图像转换工具
# 定义一个转换操作,将图像数据转换为 PyTorch 张量
transform = torchvision.transforms.ToTensor() # ToTensor 将 PIL Image 或者 numpy.ndarray 转换为 torch.FloatTensor (C x H x W),并且数值归一化到 [0,1] 区间
# 加载训练数据集:MNIST 数据集包含手写数字图片(0-9),每张图片是 28x28 像素的灰度图
trainset = torchvision.datasets.MNIST(root='./data', # 指定数据存放目录
train=True, # True 表示加载训练集
download=True, # 如果本地没有该数据集,则自动下载
transform=transform) # 应用于数据集图像的转换操作
# 创建 DataLoader 对象,用于批量加载数据,并支持多线程读取和数据打乱
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=4, # 每个批次包含的样本数量
shuffle=True) # 在每个 epoch 开始前是否对数据进行重新排序(有助于提高模型的泛化能力)
# 同样加载测试数据集,但这次设置 train=False 以加载测试集
testset = torchvision.datasets.MNIST(root='./data',
train=False,
download=True,
transform=transform)
# 测试数据不需要打乱顺序,所以 shuffle=False
testloader = torch.utils.data.DataLoader(testset,
batch_size=4,
shuffle=False)
# 遍历训练数据集的一个批次,打印出第一个批次的数据形状和标签
for x, y in trainloader:
print("训练集样本形状:", x.shape, "训练集样本标签:", y) # 输出会显示类似 torch.Size([4, 1, 28, 28]) 和对应的标签 tensor([5, 0, 4, 1])
break # 只查看第一个批次,然后退出循环
# 类似的,遍历测试数据集的一个批次
for x, y in testloader:
print("测试集样本形状:", x.shape, "测试集样本标签:", y) # 输出同样会显示类似 torch.Size([4, 1, 28, 28]) 和对应的标签 tensor([7, 2, 1, 0])
break # 只查看第一个批次,然后退出循环
2.数据增强与转换
2.1固定转换
边缘补充像素(Pad)

# 假设 T 是 torchvision.transforms 的缩写,并且已经导入 # 假设 orig_img 已经定义,代表原始的输入图像 # 对一系列指定的 padding 值,对原图进行填充处理 # 注意:这里的 "padding-padding" 应该是一个笔误,正确的应该是 "padding" padded_imgs = [ T.Pad(padding=padding)(orig_img) # 使用 torchvision.transforms 的 Pad 变换对图像进行填充 for padding in (3, 10, 30, 50) # 循环使用不同的 padding 值 ] # 调用 plot 函数来展示所有经过不同 padding 处理后的图像 plot(padded_imgs) # 假定 plot 函数能接受一个图像列表并将其可视化尺寸变换(Resize)

resized_imgs = [ T.Resize(size=size)(orig_img) # 对 orig_img 应用 Resize 变换 for size in (30, 50, 100, orig_img.size) # 尺寸包括三个整数和原图尺寸(后者可能用于对比) ] # 绘制所有缩放后的图像 plot(resized_imgs)中心截取(CenterCrop)

# 对原图进行不同尺寸的中心裁剪 center_crops = [ T.CenterCrop(size=size)(orig_img) # 使用 CenterCrop 进行中心裁剪 for size in (30, 50, 100, orig_img.size) # 裁剪尺寸包括三个整数和原图尺寸 ] # 可视化所有裁剪结果 plot(center_crops)顶角及中心截取(FiveCrop)

# 使用 FiveCrop 对原图进行五区域裁剪:四个角 + 中心 (top_left, top_right, bottom_left, bottom_right, center) = T.FiveCrop(size=(100, 100))(orig_img) # 将裁剪出的五张图像组成列表并绘制 plot([top_left, top_right, bottom_left, bottom_right, center])尺灰度变换(GrayScale)

# 将原图转换为灰度图像(T.Grayscale 是 torchvision 中的标准变换) gray_img = T.Grayscale()(orig_img) # 绘制灰度图像,指定 colormap 为 'gray' plot([gray_img], cmap='gray')
2.2概率控制的转换
随机垂直翻转(RandomHorizontalFlip)

# 定义随机水平翻转操作,概率为0.5 hflipper = T.RandomHorizontalFlip(p=0.5) # 对原始图像进行4次随机水平翻转,注意这里的下划线是为了循环4次,但不使用循环变量 transformed_imgs = [hflipper(orig_img) for _ in range(4)] plot(transformed_imgs)随机水平翻转(RandomVerticalFlip)

# 定义随机垂直翻转操作,概率为0.5 vflipper = T.RandomVerticalFlip(p=0.5) # 对原始图像进行4次随机垂直翻转,注意这里的下划线是为了循环4次,但不使用循环变量 transformed_imgs = [vflipper(orig_img) for _ in range(4)] plot(transformed_imgs)随机应用(RandomApply)

# 定义随机应用变换,概率为0.5 applier = T.RandomApply(transforms=[T.RandomCrop(size=(64, 64))], p=0.5) # 对原始图像进行4次处理,注意这里的下划线是为了循环4次,但不使用循环变量 transformed_imgs = [applier(orig_img) for _ in range(4)] # 展示转换后的图像 fig, ax = plt.subplots(1, len(transformed_imgs), figsize=(15, 5)) for i, img in enumerate(transformed_imgs): # 注意: 如果图像是PIL格式,可以直接imshow; 如果是Tensor格式,可能需要适当转换 # 这里假设img是PIL Image或可以转换成numpy数组的类型 ax[i].imshow(img) ax[i].axis('off') plt.show()总览
from PIL import Image from pathlib import Path import matplotlib.pyplot as plt import numpy as np import torch import torchvision.transforms as T plt.rcParams["savefig.bbox"] = 'tight' # orig_img = Image.open(Path('assets') / 'astronaut.jpg') # orig_img = Image.open('image.jpeg') orig_img = Image.open('image.png') # if you change the seed, make sure that the randomly-applied transforms # properly show that the image can be both transformed and *not* transformed! torch.manual_seed(0) def plot(imgs, title, with_orig=True, row_title=None, **imshow_kwargs): if not isinstance(imgs[0], list): # Make a 2d grid even if there's just 1 row imgs = [imgs] num_rows = len(imgs) num_cols = len(imgs[0]) + with_orig fig, axs = plt.subplots(nrows=num_rows, ncols=num_cols, squeeze=False) plt.title(title) for row_idx, row in enumerate(imgs): row = [orig_img] + row if with_orig else row for col_idx, img in enumerate(row): ax = axs[row_idx, col_idx] ax.imshow(np.asarray(img), **imshow_kwargs) ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[]) if with_orig: axs[0, 0].set(title='Original image') axs[0, 0].title.set_size(8) if row_title is not None: for row_idx in range(num_rows): axs[row_idx, 0].set(ylabel=row_title[row_idx]) plt.tight_layout() plt.show() # 边缘补充 padded_imgs = [T.Pad(padding=padding)(orig_img) for padding in (3, 10, 30, 50)] plot(padded_imgs,"T.pad") # 尺寸变换 resized_imgs = [T.Resize(size=size)(orig_img) for size in (30, 50, 100, orig_img.size)] plot(resized_imgs,title='Resize') # 中心截取 center_crops = [T.CenterCrop(size=size)(orig_img) for size in (30, 50, 100, orig_img.size)] plot(center_crops,title='CenterCrop') # 四角及中间截取 (top_left, top_right, bottom_left, bottom_right, center) = T.FiveCrop(size=(100, 100))(orig_img) plot([top_left, top_right, bottom_left, bottom_right, center],title='FiveCrop') # 灰度变换 gray_img = T.Grayscale()(orig_img) plot([gray_img], cmap='gray',title='Grayscale') # 颜色抖动转换 jitter = T.ColorJitter(brightness=.5, hue=.3) jitted_imgs = [jitter(orig_img) for _ in range(4)] plot(jitted_imgs,title='ColorJitter') # 高斯模糊 blurrer = T.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)) blurred_imgs = [blurrer(orig_img) for _ in range(4)] plot(blurred_imgs,title='GaussianBlur') # 随机透视变换 perspective_transformer = T.RandomPerspective(distortion_scale=0.6, p=1.0) perspective_imgs = [perspective_transformer(orig_img) for _ in range(4)] plot(perspective_imgs,title='RandomPerspective') # 随机旋转 rotater = T.RandomRotation(degrees=(0, 180)) rotated_imgs = [rotater(orig_img) for _ in range(4)] plot(rotated_imgs,title='RandomRotation') # 随机仿射变换 affine_transfomer = T.RandomAffine(degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75)) affine_imgs = [affine_transfomer(orig_img) for _ in range(4)] plot(affine_imgs,title='RandomAffine') # 弹性变换 elastic_transformer = T.ElasticTransform(alpha=250.0) transformed_imgs = [elastic_transformer(orig_img) for _ in range(2)] plot(transformed_imgs,title='ElasticTransform') # 随机裁剪 cropper = T.RandomCrop(size=(128, 128)) crops = [cropper(orig_img) for _ in range(4)] plot(crops,title='RandomCrop') # 随机缩放裁剪 resize_cropper = T.RandomResizedCrop(size=(32, 32)) resized_crops = [resize_cropper(orig_img) for _ in range(4)] plot(resized_crops,title='RandomResizedCrop') # 随机颜色翻转 inverter = T.RandomInvert() invertered_imgs = [inverter(orig_img) for _ in range(4)] plot(invertered_imgs,title='RandomInvert') # 随机海报化 posterizer = T.RandomPosterize(bits=2) posterized_imgs = [posterizer(orig_img) for _ in range(4)] plot(posterized_imgs,title='RandomPosterize') # 随机调节锐利度 sharpness_adjuster = T.RandomAdjustSharpness(sharpness_factor=2) sharpened_imgs = [sharpness_adjuster(orig_img) for _ in range(4)] plot(sharpened_imgs,title='RandomAdjustSharpness') # 随机调节对比度 autocontraster = T.RandomAutocontrast() autocontrasted_imgs = [autocontraster(orig_img) for _ in range(4)] plot(autocontrasted_imgs,title='RandomAutocontrast') # 随机直方图均衡 equalizer = T.RandomEqualize() equalized_imgs = [equalizer(orig_img) for _ in range(4)] plot(equalized_imgs,title='RandomEqualize') augmenter = T.RandAugment() imgs = [augmenter(orig_img) for _ in range(4)] plot(imgs,title='RandAugment') # 随机垂直翻转 hflipper = T.RandomHorizontalFlip(p=0.5) transformed_imgs = [hflipper(orig_img) for _ in range(4)] plot(transformed_imgs,title='RandomHorizontalFlip') # 随机水平翻转 vflipper = T.RandomVerticalFlip(p=0.5) transformed_imgs = [vflipper(orig_img) for _ in range(4)] plot(transformed_imgs,title='RandomVerticalFlip') # 随机应用 applier = T.RandomApply(transforms=[T.RandomCrop(size=(64, 64))], p=0.5) transformed_imgs = [applier(orig_img) for _ in range(4)] plot(transformed_imgs,title='RandomApply')
2.3随机转换
颜色抖动(ColorJitter)

# 定义颜色抖动变换 jitter = T.ColorJitter(brightness=.5, hue=.3) # 对原始图像应用颜色抖动变换4次 jitted_imgs = [jitter(orig_img) for _ in range(4)] plot(jitted_imgs)高斯模糊(GaussianBlur)

# 定义高斯模糊变换 blurrer = T.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)) # 对原始图像应用高斯模糊变换4次 blurred_imgs = [blurrer(orig_img) for _ in range(4)] plot(blurred_imgs)随机透视变换(RandomPerspective)

# 定义随机透视变换(始终应用,p=1.0) perspective_transformer = T.RandomPerspective(distortion_scale=0.6, p=1.0) # 对原始图像应用透视变换4次 perspective_imgs = [perspective_transformer(orig_img) for _ in range(4)] plot(perspective_imgs)随机旋转(RandomRotation)

# 定义随机旋转变换,旋转角度范围为0到180度 rotater = T.RandomRotation(degrees=(0, 180)) # 对原始图像应用随机旋转变换4次 rotated_imgs = [rotater(orig_img) for _ in range(4)] plot(rotated_imgs)随机仿射变换(RandomAffine)

# 定义随机仿射变换:旋转、平移和缩放 affine_transformer = T.RandomAffine(degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75)) # 对原始图像应用随机仿射变换4次 affine_imgs = [affine_transformer(orig_img) for _ in range(4)] plot(affine_imgs)弹性变换(ElasticTransform)

# 定义弹性变形变换 elastic_transformer = T.ElasticTransform(alpha=250.0) # 对原始图像应用弹性变形变换2次 transformed_imgs = [elastic_transformer(orig_img) for _ in range(2)] plot(transformed_imgs)随机裁剪(RandomCrop)

# 定义随机裁剪变换,裁剪尺寸为 128x128 cropper = T.RandomCrop(size=(128, 128)) # 对原始图像进行4次随机裁剪 crops = [cropper(orig_img) for _ in range(4)] plot(crops)随机缩放裁剪(RandomResizedCrop)

# 定义随机调整大小并裁剪的变换,输出尺寸为 32x32 resize_cropper = T.RandomResizedCrop(size=(32, 32)) # 对原始图像应用随机缩放裁剪4次 resized_crops = [resize_cropper(orig_img) for _ in range(4)] plot(resized_crops)随机颜色翻转(RandomInvert)

# 定义随机颜色反转变换(以50%概率反转图像颜色) inverter = T.RandomInvert() # 对原始图像应用随机反转4次 inverted_imgs = [inverter(orig_img) for _ in range(4)] plot(inverted_imgs)随机海报化 (RandomPosterize)

# 定义随机海报化变换,保留2位颜色深度 posterizer = T.RandomPosterize(bits=2) # 对原始图像应用随机海报化4次 posterized_imgs = [posterizer(orig_img) for _ in range(4)] plot(posterized_imgs)随机锐利度调整(RandomAdjustSharpness)

# 定义随机锐度调整变换,锐度因子为2 sharpness_adjuster = T.RandomAdjustSharpness(sharpness_factor=2) # 对原始图像应用随机锐度调整4次 sharpened_imgs = [sharpness_adjuster(orig_img) for _ in range(4)] plot(sharpened_imgs)随机对比度调整(RandomAutocontrast)

# 定义随机自动对比度变换 autocontraster = T.RandomAutocontrast() # 对原始图像应用随机自动对比度调整4次 autocontrasted_imgs = [autocontraster(orig_img) for _ in range(4)] plot(autocontrasted_imgs)随机直方图均衡化(RandomEqualize)

# 定义随机直方图均衡化变换 equalizer = T.RandomEqualize() # 对原始图像应用随机直方图均衡化4次 equalized_imgs = [equalizer(orig_img) for _ in range(4)] plot(equalized_imgs)随机图像增强(RandAugment)

# 定义 RandAugment 自动增强策略 augmenter = T.RandAugment() # 对原始图像应用 RandAugment 增强4次 imgs = [augmenter(orig_img) for _ in range(4)] plot(imgs)
2.4综合案例
对图像进行数据增强,将增强后的图片保存到本地文件夹

import os import cv2 as cv from torch.utils.data import DataLoader, Dataset import torch import numpy as np from torchvision import transforms from torch.nn import Sequential # 定义一系列图像变换操作:高斯模糊、随机垂直翻转、随机水平翻转 transform = Sequential( transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)), # 高斯模糊 transforms.RandomVerticalFlip(p=0.5), # 以50%的概率进行垂直翻转 transforms.RandomHorizontalFlip(p=0.2) # 以20%的概率进行水平翻转 ) class MyDataset(Dataset): def __init__(self): """ 初始化数据集:读取指定目录下的所有文件,并保存其路径。 """ root_data = "dataset" # 数据集根目录 self.file_name_list = [] # 存储所有图像文件的完整路径 for root, dirs, files in os.walk(root_data): # 遍历数据集目录 for file_i in files: file_i_full_path = os.path.join(root, file_i) # 获取文件完整路径 self.file_name_list.append(file_i_full_path) # 将路径加入列表 def __len__(self): """ 返回数据集中样本的数量。 """ return len(self.file_name_list) def __getitem__(self, item): """ 根据索引加载并处理一个样本(图像)。 :param item: 索引 :return: 处理后的图像张量和新的文件存储位置 """ file_i_loc = self.file_name_list[item] # 获取当前样本的路径 image_i = cv.imread(file_i_loc) # 读取图像 image_i = cv.cvtColor(image_i, cv.COLOR_BGR2RGB) # 转换颜色空间从BGR到RGB image_i = cv.resize(image_i, dsize=(256, 256)) # 调整图像大小为256x256 image_i = np.transpose(image_i, (2, 0, 1)) # 调整维度顺序以适应PyTorch Tensor格式 image_i_tensor = torch.from_numpy(image_i) # 转换为PyTorch Tensor image_i_tensor = transform(image_i_tensor) # 应用预定义的变换 file_i_loc_info = file_i_loc.split(os.sep) # 分割文件路径 file_i_loc_info[0] = new_root # 更新根目录为新位置 new_file_i_loc = os.path.join(*file_i_loc_info) # 生成新的文件路径 return image_i_tensor, new_file_i_loc # 返回处理后的图像及其新的存储位置 if __name__ == '__main__': new_root = 'my_new_dataset' # 新的数据集存储位置 my_dataset = MyDataset() # 创建自定义数据集实例 my_dataloader = DataLoader(my_dataset) # 创建DataLoader实例用于批量加载数据 for x_i, loc_i in my_dataloader: # 遍历dataloader x_i = x_i.view(3, 256, 256) # 调整张量形状 print(x_i.shape, loc_i) # 打印当前批次图像尺寸和存储位置 loc_info = loc_i[0].split(os.sep) # 分割文件路径信息 file_dir = os.path.join(loc_info[0], loc_info[1]) # 构造目录路径 if not os.path.isdir(file_dir): # 如果目录不存在,则创建 os.makedirs(file_dir) image = transforms.ToPILImage()(x_i) # 将Tensor转换为PIL Image image.save(loc_i[0]) # 保存图像到新位置 # 注释掉的代码是用于显示图像的,可以根据需要启用 # cv.imshow('img_i', image_i) # cv.waitKey(500)
三、网络模型搭建实战
1.网络模型搭建实战
1.1神经网络的模板
需要有以下元素组成
import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super().__init__() # 定义卷积层 # in_channels=1: 输入通道数(灰度图像) # out_channels=2: 输出通道数(卷积核数量) # kernel_size=3: 卷积核大小3×3 self.conv_1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=3) # 定义ReLU激活函数(带参数用nn,不带参数用F) # nn.ReLU() 是类,需要实例化 self.relu = nn.ReLU() def forward(self, x): # 前向传播:先卷积,后ReLU激活 x = self.relu(self.conv_1(x)) return x
1.2神经网络中各种层
全连接层
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None) # 参数说明: # in_features: 输入特征的数量 # out_features: 输出特征的数量 # bias: 是否使用偏置项(默认True) # device: 设备(如CPU/GPU,默认None) # dtype: 数据类型(默认None)import torch import torch.nn as nn m = nn.Linear(2, 3) # 创建线性层:输入维度2,输出维度3 input = torch.randn(5, 2) # 生成随机输入数据:batch_size=5,特征维度=2 output = m(input) # 前向传播:通过线性层计算输出 print(output.size()) # 打印输出张量的尺寸
上机代码
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchsummary import summary # 用于显示模型结构信息
# 定义神经网络模型类
class Model(nn.Module):
def __init__(self):
super().__init__() # 调用父类构造函数
self.fc_0 = nn.Linear(100, 10, bias=False) # 全连接层1:输入100维,输出10维,无偏置
self.fc_1 = nn.Linear(10, 5, bias=False) # 全连接层2:输入10维,输出5维,无偏置
self.fc_2 = nn.Linear(5, 1, bias=False) # 全连接层3:输入5维,输出1维,无偏置
def forward(self, x):
x = self.fc_0(x) # 通过第一层全连接层
x = self.fc_1(x) # 通过第二层全连接层
x = self.fc_2(x) # 通过第三层全连接层
return x # 返回最终输出结果
if __name__ == '__main__': # 主程序入口
model = Model() # 创建模型实例
print(model) # 打印模型结构
input = torch.rand(100) # 生成100维随机输入张量
output = model(input) # 前向传播计算输出
print(output) # 打印输出结果
summary(model, (100,)) # 显示模型详细结构信息,输入形状为(100,)
激活函数
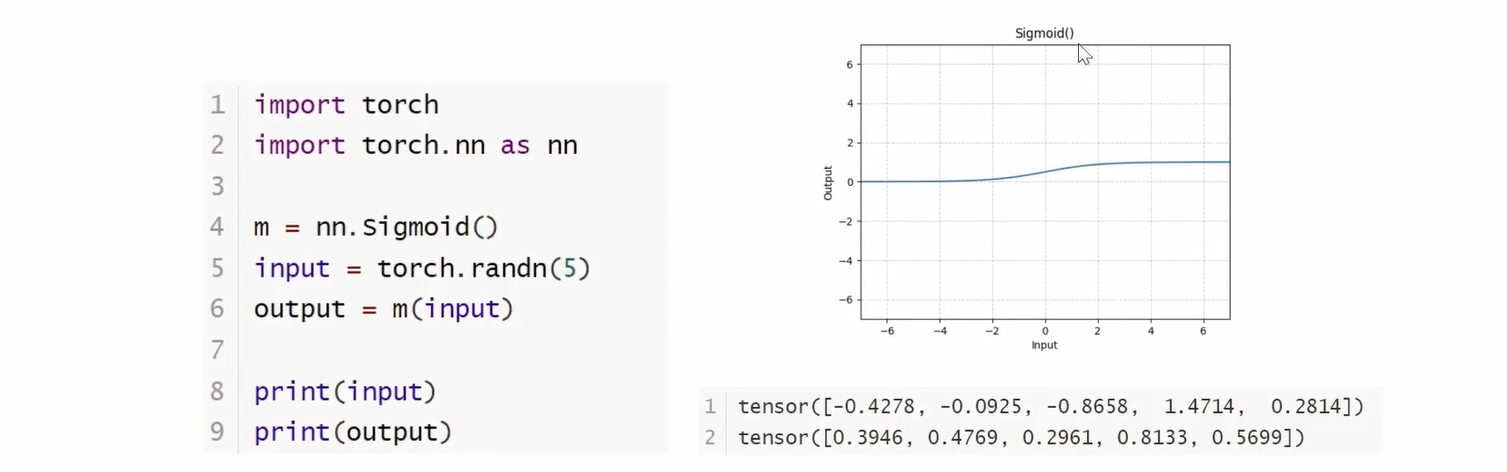
Sigmoid
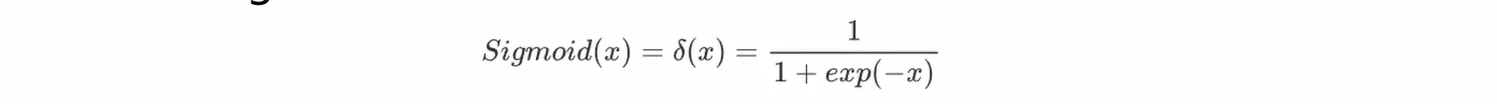
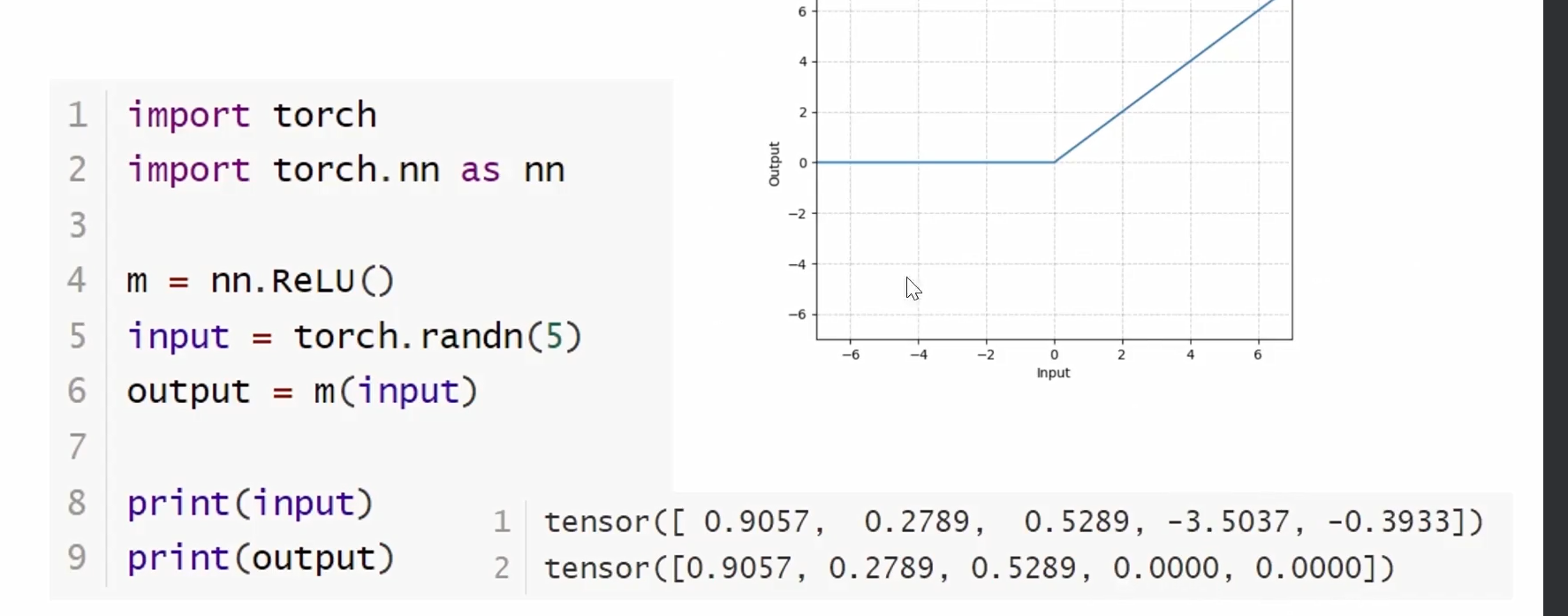
ReLU
Softmax

缓解过拟合
随机失活Dropout
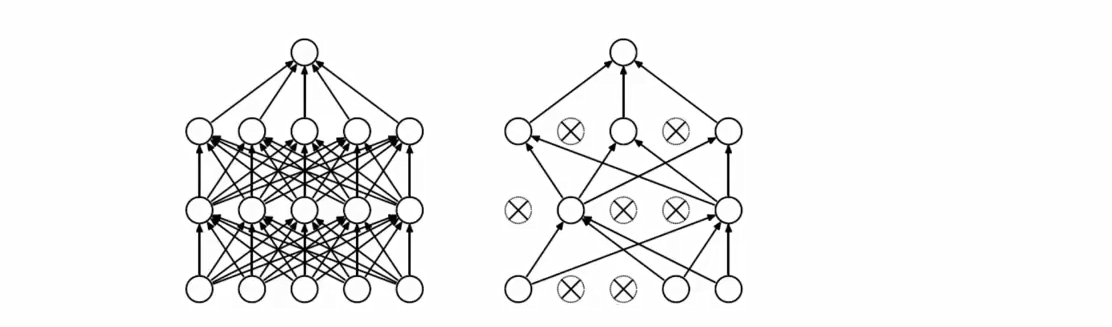
import torch import torch.nn as nn # 定义一个 Dropout 层,丢弃概率为 0.5 m = nn.Dropout(p=0.5) # 创建一个形状为 (6, 8) 的随机输入张量 input = torch.randn(6, 8) # 对输入应用 Dropout output = m(input) # 打印原始输入和经过 Dropout 后的输出 print(input) print(output) tensor([[ 1.1522, -0.2846, -0.1996, 0.0654, -0.2757, -0.1698, -0.3561, -0.4459], [-0.3006, 0.5380, -0.2264, -0.8027, -0.8712, -0.6639, -0.3515, 0.4938], [ 0.7066, -0.0320, -0.1874, 0.0929, 0.4388, -0.1596, -1.4315, -0.7959], [-0.1350, 0.8479, 1.9788, 1.0998, -0.8987, -0.8373, -1.5064, -2.0667], [-0.8998, 0.1549, -0.3013, 2.4603, 1.8944, 1.2132, -1.5923, 0.3681], [-0.7419, -0.5169, -0.3359, 0.1493, 0.1471, 0.7444, 0.1898, 0.5700]]) tensor([[ 0.0000, -0.0000, -0.3991, 0.0000, -0.0000, -0.3395, -0.7122, -0.0000], [-0.0000, 0.0000, -0.4529, -0.0000, -0.0000, -1.3278, -0.0000, 0.9877], [ 0.0000, -0.0000, -0.3748, 0.0000, 0.8775, -0.0000, -2.8631, -0.0000], [-0.0000, 0.0000, 3.9576, 2.1996, -1.7973, -1.6746, -3.0129, -4.1334], [-1.7996, 0.3097, -0.0000, 0.0000, 3.7888, 0.0000, -0.0000, 0.7362], [-0.0000, -1.0337, -0.0000, 0.2986, 0.2942, 0.0000, 0.3795, 0.0000]])
1.3全连接网络处理一维信息
全连接网络处理一维信息
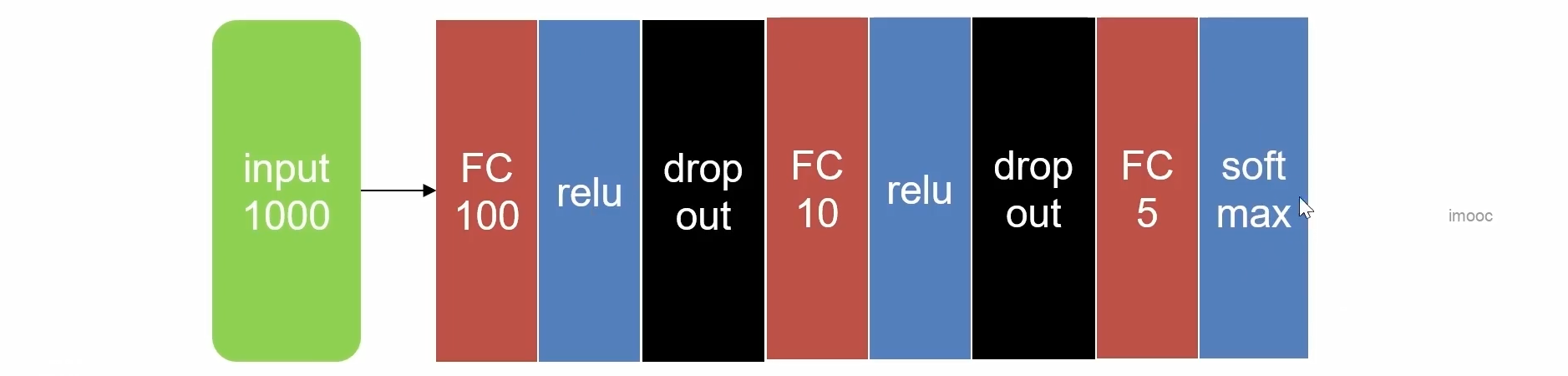
import torch import torch.nn as nn from torchsummary import summary # 定义一个简单的全连接神经网络 class NeuralNetwork(nn.Module): def __init__(self): super().__init__() # 第一个全连接层:输入1000维,输出100维 self.fc1 = nn.Linear(1000, 100) # ReLU 激活函数 self.relu = nn.ReLU() # Dropout 层,以50%的概率随机置零神经元,防止过拟合 self.dropout = nn.Dropout(0.5) # 第二个全连接层:输入100维,输出10维 self.fc2 = nn.Linear(100, 10) # 第三个全连接层:输入10维,输出5维(对应5个类别) self.fc3 = nn.Linear(10, 5) # Softmax 激活函数,将输出转换为概率分布(按第1维归一化) self.softmax = nn.Softmax(dim=1) def forward(self, x): # 输入经过第一层线性变换 x = self.fc1(x) # 应用 ReLU 激活 x = self.relu(x) # 应用 Dropout x = self.dropout(x) # 第二层线性变换 x = self.fc2(x) # 再次应用 ReLU x = self.relu(x) # 再次应用 Dropout x = self.dropout(x) # 第三层线性变换(输出层) x = self.fc3(x) # 应用 Softmax 得到类别概率 x = self.softmax(x) return x if __name__ == '__main__': # 实例化模型 model = NeuralNetwork() # 创建一个 batch_size=10、特征维度=1000 的随机输入张量 input = torch.rand((10, 1000)) # 前向传播得到输出 output = model(input) # 打印输出张量的形状(应为 [10, 5]) print(output.shape) # 打印具体的输出概率值 print(output) # 使用 torchsummary 打印模型结构(输入形状为 (1000,),表示单个样本的特征维度) summary(model, (1000,)) torch.Size([10, 5]) tensor([[0.1715, 0.2602, 0.1988, 0.1920, 0.1775], [0.1755, 0.2594, 0.1986, 0.1890, 0.1776], [0.1897, 0.2434, 0.1853, 0.2083, 0.1732], [0.1672, 0.2564, 0.2052, 0.1909, 0.1803], [0.1703, 0.2621, 0.1977, 0.1904, 0.1795], [0.1566, 0.2830, 0.2018, 0.1359, 0.2227], [0.1707, 0.2551, 0.1917, 0.1949, 0.1876], [0.1560, 0.2577, 0.2053, 0.1829, 0.1981], [0.1708, 0.2407, 0.1910, 0.2036, 0.1940], [0.1663, 0.2618, 0.2005, 0.1879, 0.1835]], grad_fn=<SoftmaxBackward0>) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Linear-1 [-1, 100] 100,100 ReLU-2 [-1, 100] 0 Dropout-3 [-1, 100] 0 Linear-4 [-1, 10] 1,010 ReLU-5 [-1, 10] 0 Dropout-6 [-1, 10] 0 Linear-7 [-1, 5] 55 Softmax-8 [-1, 5] 0 ================================================================ Total params: 101,165 Trainable params: 101,165 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.39 Estimated Total Size (MB): 0.39 ----------------------------------------------------------------
1.4全连接网络处理二维图像
全连接网络处理二维信息
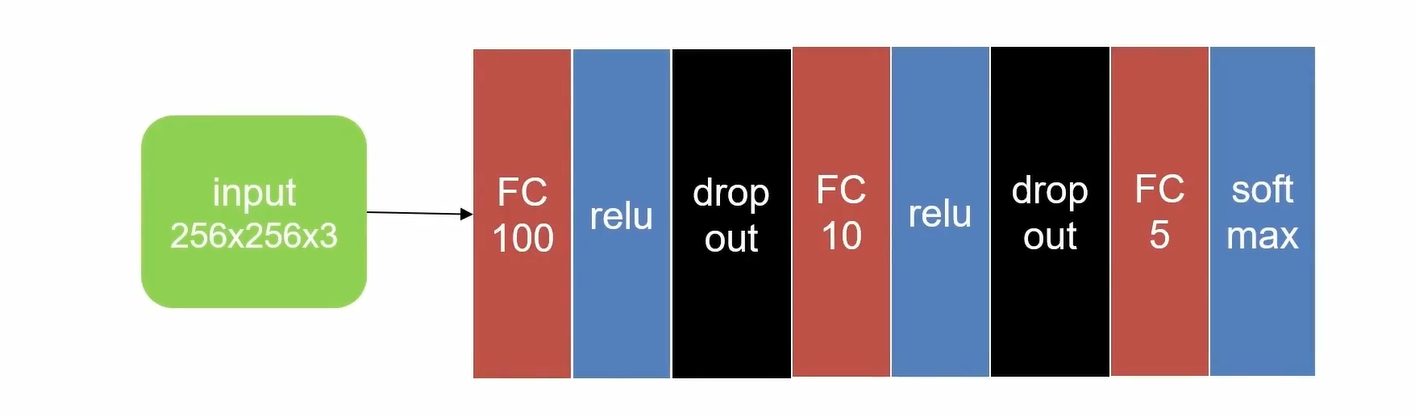
import torch import torch.nn as nn from torchsummary import summary class NeuralNetwork(nn.Module): def __init__(self): super().__init__() # 定义网络层 # 第一层全连接层:输入维度为256*256*3(196608),输出维度为100 self.fc1 = nn.Linear(256 * 256 * 3, 100) # ReLU激活函数 self.relu = nn.ReLU() # Dropout层,丢弃率为0.5,用于防止过拟合 self.dropout = nn.Dropout(0.5) # 第二层全连接层:输入维度100,输出维度10 self.fc2 = nn.Linear(100, 10) # 第三层全连接层:输入维度10,输出维度5 self.fc3 = nn.Linear(10, 5) # Softmax激活函数,dim=1表示在第一个维度(batch维度之后)上进行softmax self.softmax = nn.Softmax(dim=1) def forward(self, x): # 将输入图像展平:从(batch, 256, 256, 3)变为(batch, 256*256*3) x = x.view(-1, 256 * 256 * 3) # 第一层:全连接 + ReLU + Dropout x = self.fc1(x) x = self.relu(x) x = self.dropout(x) # 第二层:全连接 + ReLU + Dropout x = self.fc2(x) x = self.relu(x) x = self.dropout(x) # 第三层:全连接 + Softmax x = self.fc3(x) x = self.softmax(x) return x if __name__ == '__main__': # 实例化模型 model = NeuralNetwork() # 创建测试输入:10个256x256的RGB图像 input = torch.rand((10, 256, 256, 3)) # 前向传播 output = model(input) # 打印输出形状和具体值 print("输出形状:", output.shape) # 应该是(10, 5) print("输出值:", output) # 使用torchsummary打印模型结构摘要 # 注意:torchsummary期望输入形状为(通道, 高度, 宽度),而我们的输入是(高度, 宽度, 通道) # 实际使用时可能需要调整输入形状的表示方式 summary(model, (256, 256, 3)) 输出形状: torch.Size([10, 5]) 输出值: tensor([[0.1501, 0.1684, 0.2826, 0.2006, 0.1983], [0.1299, 0.1627, 0.2892, 0.2058, 0.2124], [0.1334, 0.1673, 0.2889, 0.2070, 0.2035], [0.1435, 0.1878, 0.2688, 0.1792, 0.2208], [0.1034, 0.1463, 0.3228, 0.2315, 0.1959], [0.1545, 0.1739, 0.2688, 0.1908, 0.2120], [0.1265, 0.1581, 0.3097, 0.2141, 0.1916], [0.1074, 0.1550, 0.3125, 0.2447, 0.1803], [0.1225, 0.1620, 0.2881, 0.2281, 0.1993], [0.1469, 0.1724, 0.2927, 0.1894, 0.1986]], grad_fn=<SoftmaxBackward0>) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Linear-1 [-1, 100] 19,660,900 ReLU-2 [-1, 100] 0 Dropout-3 [-1, 100] 0 Linear-4 [-1, 10] 1,010 ReLU-5 [-1, 10] 0 Dropout-6 [-1, 10] 0 Linear-7 [-1, 5] 55 Softmax-8 [-1, 5] 0 ================================================================ Total params: 19,661,965 Trainable params: 19,661,965 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.75 Forward/backward pass size (MB): 0.00 Params size (MB): 75.00 Estimated Total Size (MB): 75.76 ---------------------------------------------------------------- Process finished with exit code 0
1.5模型搭建(卷积层)
卷积层
torch.nn.Conv2d( in_channels, # 输入通道数(输入张量的通道维度大小) out_channels, # 输出通道数(卷积核的数量,即输出张量的通道维度大小) kernel_size, # 卷积核的大小(可以是整数或包含两个整数的元组 (kH, kW)) stride=1, # 卷积步长,默认为1(可以是整数或包含两个整数的元组 (sH, sW)) padding=0, # 输入四周的零填充大小,默认为0(可以是整数或包含两个整数的元组 (padH, padW)) dilation=1, # 卷积核元素之间的间距(空洞卷积),默认为1(可以是整数或包含两个整数的元组 (dH, dW)) groups=1, # 分组卷积的组数,默认为1(输入和输出通道被分为 'groups' 组,每组分别进行卷积) bias=True, # 是否添加可学习的偏置项,默认为True padding_mode='zeros', # 填充模式,默认为'zeros'(可选:'zeros', 'reflect', 'replicate', 'circular') device=None, # 张量所使用的设备(如 'cpu' 或 'cuda'),默认为None(使用当前默认设备) dtype=None # 张量的数据类型(如 torch.float32),默认为None(使用当前默认dtype) )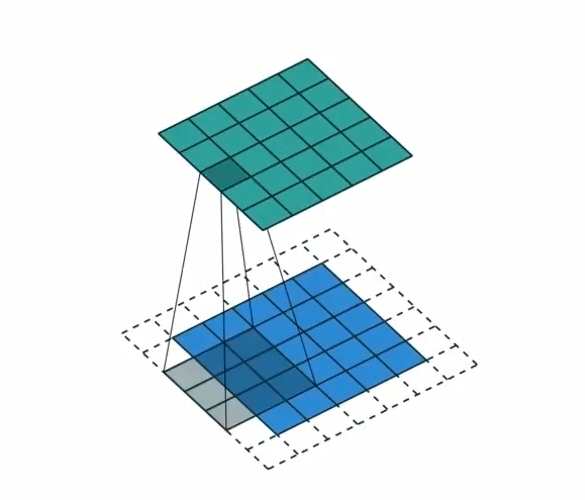
import torch import torch.nn as nn # 使用方形卷积核(3x3),以及相同的步长(stride=2) m1 = nn.Conv2d(16, 33, 3, stride=2) # 使用非方形卷积核(3x5),以及非对称的步长(2,1)和补零(4,2) m2 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) # 使用非方形卷积核(3x5),以及非对称的步长、补零和膨胀系数(dilation) m3 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1)) # 输入张量:batch_size=20, in_channels=16, height=50, width=100 input = torch.randn(20, 16, 50, 100) # 分别测试三个模块并打印输出形状 output1 = m1(input) print(output1.shape) # torch.Size([20, 33, 24, 49]) output2 = m2(input) print(output2.shape) # torch.Size([20, 33, 26, 99]) output3 = m3(input) print(output3.shape) # torch.Size([20, 33, 24, 99])转置卷积层
torch.nn.ConvTranspose2d( in_channels, # 输入通道数(输入张量的通道维度大小) out_channels, # 输出通道数(反卷积后张量的通道维度大小) kernel_size, # 卷积核(转置卷积核)的大小,可以是整数或包含两个整数的元组 (kH, kW) stride=1, # 卷积步长,默认为1,可以是整数或元组 (sH, sW) padding=0, # 输入四周在进行卷积前的零填充大小,默认为0,可以是整数或元组 (padH, padW) output_padding=0, # 在输出图像边缘额外添加的像素数,用于控制输出尺寸,默认为0,可为整数或元组 (out_padH, out_padW) groups=1, # 分组反卷积的组数,默认为1(输入和输出通道被分为 'groups' 组分别处理) bias=True, # 是否添加可学习的偏置项,默认为True dilation=1, # 卷积核元素之间的间距(空洞),默认为1,可为整数或元组 (dH, dW) padding_mode='zeros', # 填充模式,但注意:ConvTranspose2d 实际上不支持除 'zeros' 外的其他 padding_mode,此参数保留仅为接口一致性 device=None, # 张量所使用的设备(如 'cpu' 或 'cuda'),默认为None(使用当前默认设备) dtype=None # 张量的数据类型(如 torch.float32),默认为None(使用当前默认dtype) )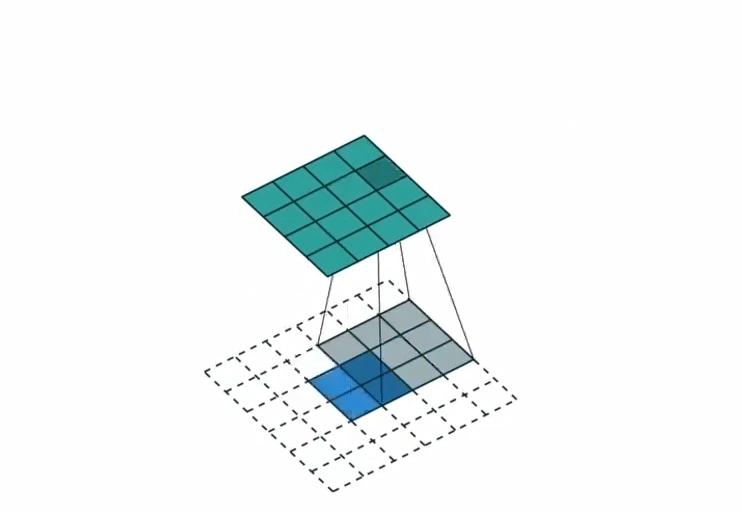
import torch.nn as nn import torch # 使用长宽一致的卷积核以及相同的步长 m = nn.ConvTranspose2d(16, 33, 3, stride=2) # 使用长宽不一致的卷积核,步长,以及补零 m = nn.ConvTranspose2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) input = torch.randn(20, 16, 50, 100) output = m(input) print(output.shape) # 可以直接指明输出的尺寸大小 input = torch.randn(1, 16, 12, 12) downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1) upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1) h = downsample(input) print(h.size()) output = upsample(h, output_size=input.size()) print(output.size())
1.6搭建全卷积网络结构
全卷积网络实现图像分割
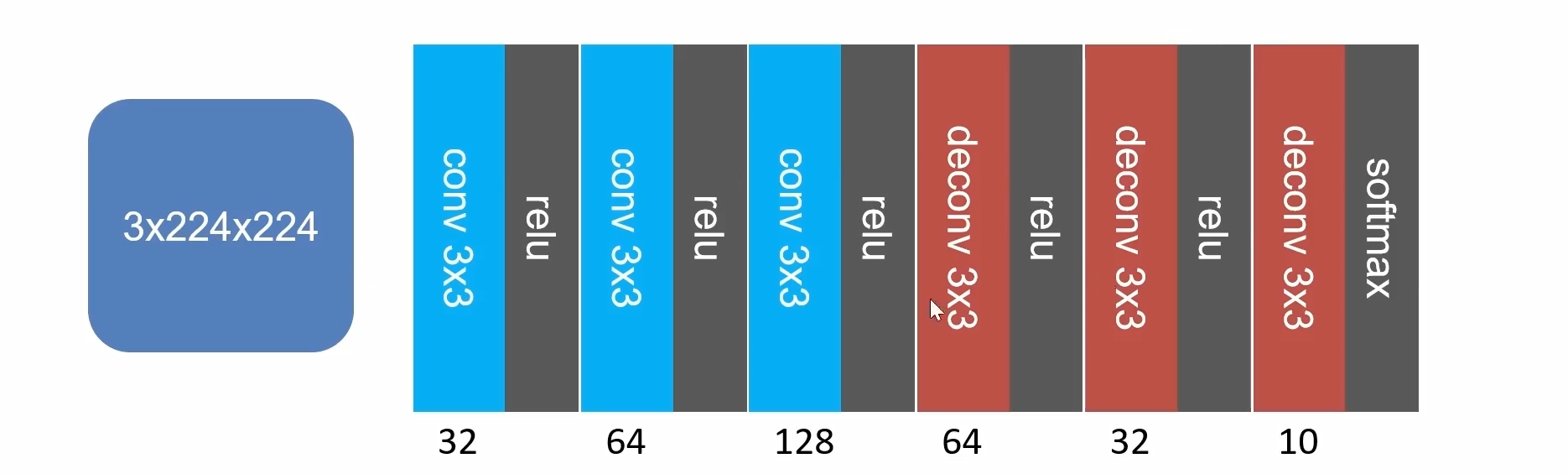
import torch import torch.nn as nn from torchsummary import summary # 用于打印模型结构和参数量 # 定义全卷积网络(FCN)模型类 class FCN(nn.Module): def __init__(self): super().__init__() # 调用父类 nn.Module 的初始化方法 # 第一个卷积层:输入通道3(如RGB图像),输出通道32,卷积核大小3×3,stride=1, padding=0(默认) self.conv_1 = nn.Conv2d(3, 32, 3) # ReLU 激活函数 self.relu = nn.ReLU() # 第二个卷积层:输入32通道,输出64通道,卷积核3×3 self.conv_2 = nn.Conv2d(32, 64, 3) # 第三个卷积层:输入64通道,输出128通道,卷积核3×3 self.conv_3 = nn.Conv2d(64, 128, 3) # 第一个转置卷积层(上采样):输入128通道,输出64通道,卷积核3×3 self.deconv_1 = nn.ConvTranspose2d(128, 64, 3) # 第二个转置卷积层:输入64通道,输出32通道,卷积核3×3 self.deconv_2 = nn.ConvTranspose2d(64, 32, 3) # 第三个转置卷积层:输入32通道,输出10通道(如10类分割),卷积核3×3 self.deconv_3 = nn.ConvTranspose2d(32, 10, 3) # Softmax 激活函数,对每个像素的10个通道做归一化(用于语义分割) self.softmax = nn.Softmax(dim=1) # dim=1 表示在通道维度上应用 softmax def forward(self, x): # 前向传播过程 x = self.conv_1(x) # 卷积 x = self.relu(x) # 激活 x = self.conv_2(x) # 卷积 x = self.relu(x) # 激活 x = self.conv_3(x) # 卷积 x = self.relu(x) # 激活 x = self.deconv_1(x) # 转置卷积(上采样) x = self.relu(x) # 激活 x = self.deconv_2(x) # 转置卷积 x = self.relu(x) # 激活 x = self.deconv_3(x) # 转置卷积,输出10通道 x = self.softmax(x) # 对每个空间位置的10个类别做概率归一化 return x # 返回形状为 (N, 10, H_out, W_out) 的张量 if __name__ == '__main__': model = FCN() # 实例化模型 input = torch.rand((10, 3, 224, 224)) # 创建随机输入:batch_size=10, 3通道, 224×224 output = model(input) # 前向传播 print(output.shape) # 打印输出张量形状(注意:由于无 padding,尺寸会缩小) print(model) # 打印模型各层结构 summary(model, (3, 224, 224)) # 使用 torchsummary 打印模型参数量和每层输出尺寸
1.7卷积+全连接网络
卷积+全连接网络实现图像分类
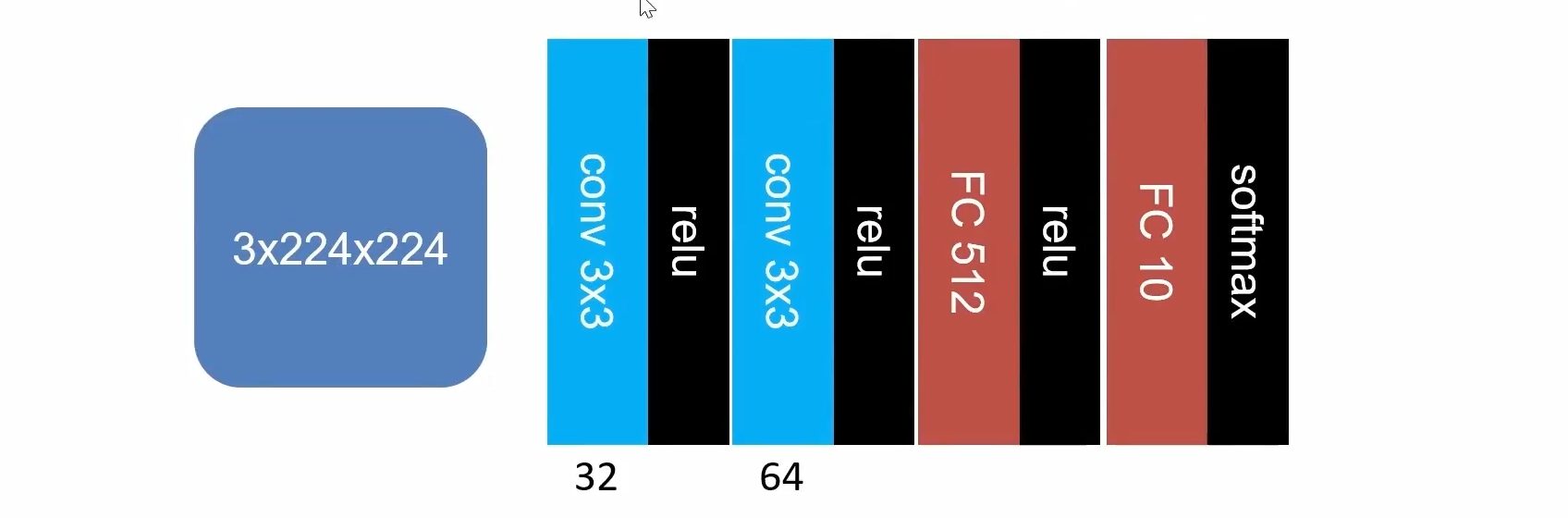
import torch import torch.nn as nn from torchsummary import summary # 用于打印模型结构、参数量和每层输出形状 # 定义一个简单的卷积神经网络(ConvNet) class ConvNet(nn.Module): def __init__(self): super().__init__() # 调用父类 nn.Module 的初始化方法 # 第一个卷积层:输入通道=3(如RGB图像),输出通道=32,卷积核大小=3×3(默认 stride=1, padding=0) self.conv_1 = nn.Conv2d(3, 32, 3) # ReLU 激活函数 self.relu = nn.ReLU() # 第二个卷积层:输入通道=32,输出通道=64,卷积核大小=3×3 self.conv_2 = nn.Conv2d(32, 64, 3) # 全连接层1:输入维度=64*220*220,输出维度=512 # 注:220 来自输入 224×224 经过两次无 padding 的 3×3 卷积后尺寸变化: # 第一次卷积后:224 - 2 = 222 # 第二次卷积后:222 - 2 = 220 self.fc_1 = nn.Linear(64 * 220 * 220, 512) # 全连接层2:将512维映射到10类(如CIFAR-10或ImageNet子集) self.fc_2 = nn.Linear(512, 10) # Softmax 激活函数,在类别维度(dim=1)上归一化输出为概率分布 self.softmax = nn.Softmax(dim=1) def forward(self, x): # 前向传播过程 x = self.conv_1(x) # 应用第一个卷积层 x = self.relu(x) # ReLU 激活 x = self.conv_2(x) # 应用第二个卷积层 x = self.relu(x) # ReLU 激活 # 将卷积输出展平为一维向量,以便输入全连接层 # batch_size 保持不变(-1 表示自动推断),特征维度变为 64*220*220 x = x.view(-1, 64 * 220 * 220) x = self.fc_1(x) # 全连接层1 x = self.relu(x) # ReLU 激活 x = self.fc_2(x) # 全连接层2(输出10维 logits) x = self.softmax(x) # 转换为概率分布(每行和为1) return x # 返回形状为 (batch_size, 10) 的张量 if __name__ == '__main__': input = torch.rand((5, 3, 224, 224)) # 创建随机输入:batch_size=5, 3通道, 224×224 图像 model = ConvNet() # 实例化模型 output = model(input) # 前向传播 print(output.shape) # 打印输出形状,应为 torch.Size([5, 10]) print(model) # 打印模型各层结构 summary(model, (3, 224, 224)) # 使用 torchsummary 显示模型详细信息(参数量、输出尺寸等) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 222, 222] 896 ReLU-2 [-1, 32, 222, 222] 0 Conv2d-3 [-1, 64, 220, 220] 18,496 ReLU-4 [-1, 64, 220, 220] 0 Linear-5 [-1, 512] 1,585,971,712 ReLU-6 [-1, 512] 0 Linear-7 [-1, 10] 5,130 Softmax-8 [-1, 10] 0 ================================================================
1.8池化层和BN层
池化层(最大池化)
torch.nn.MaxPool2d( kernel_size, # 池化窗口的大小,可以是整数(如 2 表示 2×2)或包含两个整数的元组 (kH, kW) stride=None, # 池化窗口移动的步长;若为 None,则默认等于 kernel_size padding=0, # 在输入四周进行零填充的大小,可以是整数或元组 (padH, padW) dilation=1, # 池化窗口内元素的间距(空洞池化),目前 PyTorch 的 MaxPool2d 不支持 dilation > 1(仅用于接口一致性) return_indices=False, # 是否返回最大值的位置索引(用于反池化,如 nn.MaxUnpool2d),默认不返回 ceil_mode=False # 当为 True 时,使用向上取整计算输出尺寸;默认为 False(向下取整) )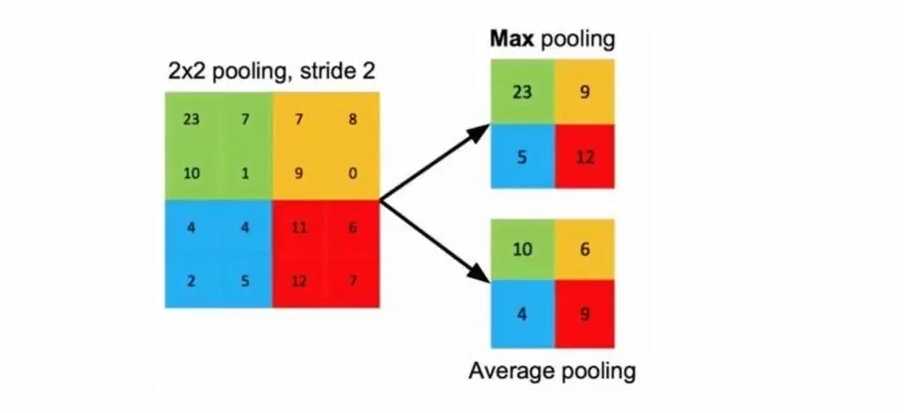
import torch import torch.nn as nn # 长宽一致的池化,核尺寸为 3x3,池化步长为 2 m1 = nn.MaxPool2d(3, stride=2) # 长宽不一致的池化,核尺寸为 3x2,步长为 (2,1) m2 = nn.MaxPool2d((3, 2), stride=(2, 1)) # 创建随机输入张量:batch=4, channel=3, height=24, width=24 input = torch.randn(4, 3, 24, 24) # 分别应用两个池化层 output1 = m1(input) output2 = m2(input) # 打印输入和输出形状 print("input.shape =", input.shape) print("output1.shape =", output1.shape) print("output2.shape =", output2.shape) input.shape = torch.Size([4, 3, 24, 24]) output1.shape = torch.Size([4, 3, 11, 11]) output2.shape = torch.Size([4, 3, 11, 23])BN层
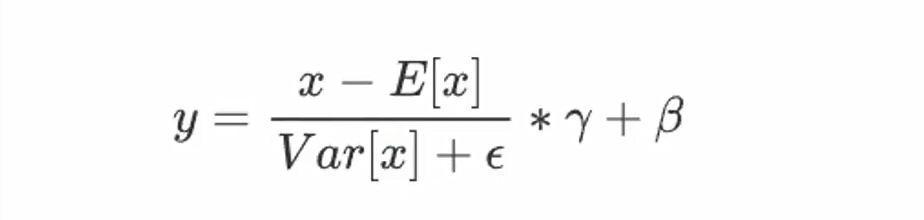
import torch import torch.nn as nn # 批量归一化层(具有可学习参数:gamma 和 beta) m_learnable = nn.BatchNorm2d(100) # 批量归一化层(不具有可学习参数,affine=False 表示不使用 gamma 和 beta) m_non_learnable = nn.BatchNorm2d(100, affine=False) # 创建随机输入张量:batch=20, channel=100, height=35, width=45 input = torch.randn(20, 100, 35, 45) # 应用具有可学习参数的批量归一化层 output_learnable = m_learnable(input) # 应用不具有可学习参数的批量归一化层 output_non_learnable = m_non_learnable(input) # 打印形状信息 print("input.shape =", input.shape) print("output_learnable.shape =", output_learnable.shape) print("output_non_learnable.shape =", output_non_learnable.shape) input.shape = torch.Size([20, 100, 35, 45]) output_learnable.shape = torch.Size([20, 100, 35, 45]) output_non_learnable.shape = torch.Size([20, 100, 35, 45])
1.9复现LeNet-5
复现LeNet-5
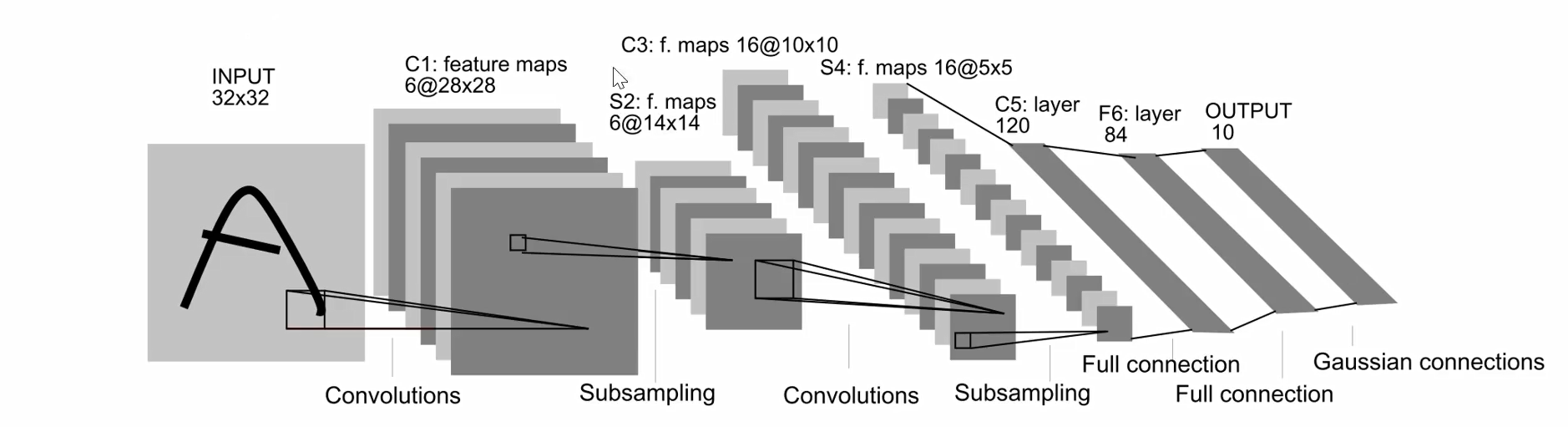
卷积核大小5x5 最大池化核大小2x2import torch.nn as nn import torch from torchsummary import summary # 用于打印模型结构和参数量 import torch.nn.functional as F # 提供函数式接口,如 softmax、relu 等 # 定义 LeNet 网络(此处为适配 32×32 RGB 图像的变体) class LeNet(nn.Module): def __init__(self): super().__init__() # 调用父类 nn.Module 的初始化方法 # 第一个卷积层:输入通道=3(RGB),输出通道=6,卷积核=5×5(默认 stride=1, padding=0) self.conv_1 = nn.Conv2d(3, 6, 5) # 第一个最大池化层:窗口大小=2×2,stride=2(默认等于 kernel_size) self.pool_1 = nn.MaxPool2d(2) # 第二个卷积层:输入=6通道,输出=16通道,卷积核=5×5 self.conv_2 = nn.Conv2d(6, 16, 5) # 第二个最大池化层:2×2 池化 self.pool_2 = nn.MaxPool2d(2) # 第三个卷积层:输入=16通道,输出=120通道,卷积核=5×5 # 注:在标准 LeNet-5 中,此层后特征图应为 1×1(当输入为 32×32 时) self.conv_3 = nn.Conv2d(16, 120, 5) # 全连接层1:输入120维(对应 conv_3 输出的 120 个 1×1 特征),输出84维 self.fc_1 = nn.Linear(120, 84) # 全连接层2:输出10维(对应10个类别,如 CIFAR-10) self.fc_2 = nn.Linear(84, 10) def forward(self, x): # 前向传播流程 x = self.conv_1(x) # 卷积 → 输出尺寸: (32−5+1)=28 → 28×28 x = self.pool_1(x) # 池化 → 28/2 = 14 → 14×14 x = self.conv_2(x) # 卷积 → 14−5+1 = 10 → 10×10 x = self.pool_2(x) # 池化 → 10/2 = 5 → 5×5 x = self.conv_3(x) # 卷积 → 5−5+1 = 1 → 输出为 (N, 120, 1, 1) # 展平:将 (N, 120, 1, 1) 变为 (N, 120) x = x.view(-1, 120) x = self.fc_1(x) # 全连接 → 120 → 84 x = self.fc_2(x) # 全连接 → 84 → 10 # 对输出应用 softmax,得到每类的概率分布(dim=1 表示在类别维度归一化) x = F.softmax(x, dim=1) return x # 返回形状为 (batch_size, 10) 的概率张量 if __name__ == '__main__': input = torch.rand((5, 3, 32, 32)) # 创建随机输入:batch=5, 3通道, 32×32(如 CIFAR-10) model = LeNet() # 实例化 LeNet 模型 output = model(input) # 前向传播 print(output.shape) # 应输出 torch.Size([5, 10]) print(model) # 打印模型各层结构 summary(model, (3, 32, 32)) # 使用 torchsummary 显示每层输出尺寸和参数量
1.10 Sequential:顺序容器
Sequential:顺序容器
import torch.nn as nn model = nn.Sequential( nn.Conv2d(1, 20, 5), # 输入1通道,输出20通道,卷积核5×5 nn.ReLU(), # ReLU 激活函数 nn.Conv2d(20, 64, 5), # 输入20通道,输出64通道,卷积核5×5 nn.ReLU() # ReLU 激活函数 )from collections import OrderedDict import torch.nn as nn # 使用 nn.Sequential 构建一个顺序模型,并通过 OrderedDict 为每一层指定名称 model = nn.Sequential(OrderedDict([ # 第一层:命名为 'conv1',是一个 2D 卷积层,输入通道数=1,输出通道数=20,卷积核大小=5×5(默认 stride=1, padding=0) ('conv1', nn.Conv2d(1, 20, 5)), # 第二层:命名为 'relu1',是 ReLU 激活函数(无参数,需实例化调用) ('relu1', nn.ReLU()), # 第三层:命名为 'conv2',2D 卷积层,输入通道=20,输出通道=64,卷积核=5×5 ('conv2', nn.Conv2d(20, 64, 5)), # 第四层:命名为 'relu2',ReLU 激活函数 ('relu2', nn.ReLU()) ]))
综合案例
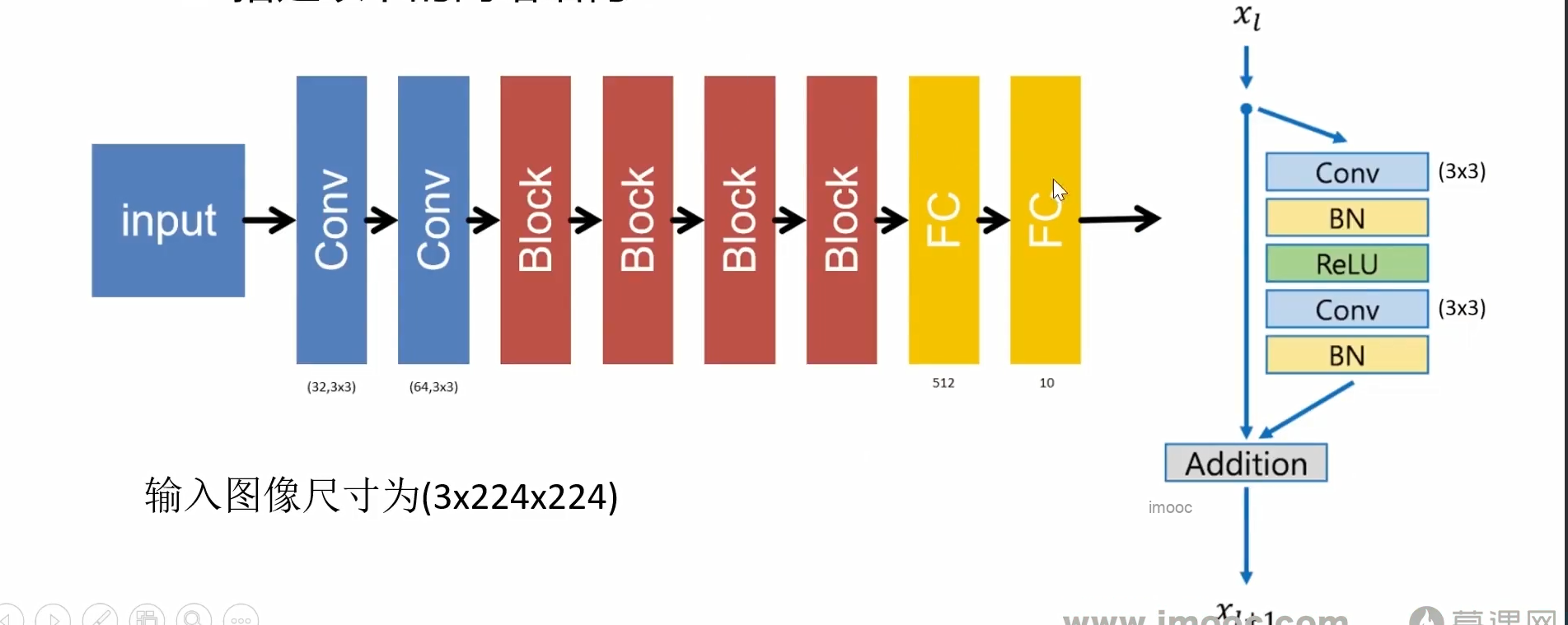
搭建以下的网络结构
import torch.nn as nn import torch from torchsummary import summary from collections import OrderedDict # 定义一个残差块(Residual Block),但注意:此实现未处理通道或尺寸不匹配的情况 class MyBlock(nn.Module): def __init__(self, in_channel, out_channel): super().__init__() # 第一个卷积层:3×3 卷积,padding=1 → 保持空间尺寸不变 self.conv_1 = nn.Conv2d(in_channel, out_channel, 3, padding=1) # 批归一化(针对第一个卷积输出) self.bn_1 = nn.BatchNorm2d(out_channel) # ReLU 激活函数 self.relu = nn.ReLU() # 第二个卷积层:3×3 卷积,padding=1 → 保持空间尺寸不变 self.conv_2 = nn.Conv2d(out_channel, out_channel, 3, padding=1) # 批归一化(针对第二个卷积输出) self.bn_2 = nn.BatchNorm2d(out_channel) def forward(self, x): x_1 = x # 保存原始输入,用于残差连接(shortcut) x = self.conv_1(x) x = self.bn_1(x) x = self.relu(x) x = self.conv_2(x) x = self.bn_2(x) result = x + x_1 # 残差连接:将卷积分支输出与原始输入相加 return result # 主网络定义 class MainNet(nn.Module): def __init__(self): super().__init__() # 初始两个卷积层(无 padding,会减小空间尺寸) self.conv_1 = nn.Conv2d(3, 32, 3) # 输入3通道(RGB),输出32通道,kernel=3×3 self.conv_2 = nn.Conv2d(32, 64, 3) # 输入32通道,输出64通道,kernel=3×3 # 主干部分:由4个 MyBlock 组成的顺序模块,每个块输入/输出均为64通道 self.body = nn.Sequential( OrderedDict([ ('block_1', MyBlock(64, 64)), ('block_2', MyBlock(64, 64)), ('block_3', MyBlock(64, 64)), ('block_4', MyBlock(64, 64)), ]) ) # 分类头(全连接层) self.tail = nn.Sequential( nn.Linear(64 * 220 * 220, 512), # 将展平后的特征映射到512维 nn.Linear(512, 10) # 映射到10个类别(如CIFAR-10) ) def forward(self, x): x = self.conv_1(x) # 第一次卷积:224→222(无 padding) x = self.conv_2(x) # 第二次卷积:222→220(无 padding) x = self.body(x) # 经过4个残差块,空间尺寸保持220×220(因 block 内 padding=1) x = x.view(-1, 64 * 220 * 220) # 展平为 (batch_size, 64*220*220) x = self.tail(x) # 全连接分类 return x # 输出形状:(batch_size, 10) # 主程序入口 if __name__ == '__main__': input = torch.rand((5, 3, 224, 224)) # 创建随机输入:batch=5, 3通道, 224×224 model = MainNet() # 实例化主网络 output = model(input) # 前向传播 print(output.shape) # 应输出 torch.Size([5, 10]) print(model) # 打印模型各层结构 summary(model, (3, 224, 224)) # 使用 torchsummary 显示每层输出尺寸和参数量 ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 222, 222] 896 Conv2d-2 [-1, 64, 220, 220] 18,496 Conv2d-3 [-1, 64, 220, 220] 36,928 BatchNorm2d-4 [-1, 64, 220, 220] 128 ReLU-5 [-1, 64, 220, 220] 0 Conv2d-6 [-1, 64, 220, 220] 36,928 BatchNorm2d-7 [-1, 64, 220, 220] 128 MyBlock-8 [-1, 64, 220, 220] 0 Conv2d-9 [-1, 64, 220, 220] 36,928 BatchNorm2d-10 [-1, 64, 220, 220] 128 ReLU-11 [-1, 64, 220, 220] 0 Conv2d-12 [-1, 64, 220, 220] 36,928 BatchNorm2d-13 [-1, 64, 220, 220] 128 MyBlock-14 [-1, 64, 220, 220] 0 Conv2d-15 [-1, 64, 220, 220] 36,928 BatchNorm2d-16 [-1, 64, 220, 220] 128 ReLU-17 [-1, 64, 220, 220] 0 Conv2d-18 [-1, 64, 220, 220] 36,928 BatchNorm2d-19 [-1, 64, 220, 220] 128 MyBlock-20 [-1, 64, 220, 220] 0 Conv2d-21 [-1, 64, 220, 220] 36,928 BatchNorm2d-22 [-1, 64, 220, 220] 128 ReLU-23 [-1, 64, 220, 220] 0 Conv2d-24 [-1, 64, 220, 220] 36,928 BatchNorm2d-25 [-1, 64, 220, 220] 128 MyBlock-26 [-1, 64, 220, 220] 0 Linear-27 [-1, 512] 1,585,971,712 Linear-28 [-1, 10] 5,130 ================================================================